
In this Chapter of Deep Learning book, we will discuss the Boltzmann Machine. It is an Unsupervised Deep Learning technique and we will discuss both theoretical and Practical Implementation from Scratch.
This chapter spans 6 parts:
Перевод
Ссылка на автора
Это руководство является частью серии из двух статей о Restricted Boltzmann Machines, мощной архитектуре глубокого обучения для совместной фильтрации. В этой части я познакомлю вас с теорией ограниченных машин Больцмана. Вторая часть состоит из пошагового руководства по практической реализации модели, которая может предсказать, хочет ли пользователь фильм или нет.
Практическая часть теперь доступна Вот,

Что такое машины Больцмана?
Машины Больцмана представляют собой стохастические и генеративные нейронные сети, способные изучать внутренние представления и способные представлять и (при наличии достаточного времени) решать сложные комбинаторные задачи.
Они названы в честь Распределение Больцмана (также известный как распределение Гиббса), который является неотъемлемой частью статистической механики и помогает нам понять влияние таких параметров, как энтропия и температура, на квантовые состояния в термодинамике. Вот почему они называются моделями на основе энергии (EBM). Они были изобретены в 1985 году Джеффри Хинтоном, тогда профессором в университете Карнеги-Меллона, и Терри Сейновски, тогда профессором в университете Джона Хопкинса
Цепь Маркова
Цепь Маркова (Markov Chain) — это математическая система, которая обрабатывает переход из одного состояния в другое на основе некоторых вероятностных правил. Вероятность перехода в какое-либо конкретное состояние зависит исключительно от текущего состояния и прошедшего времени.
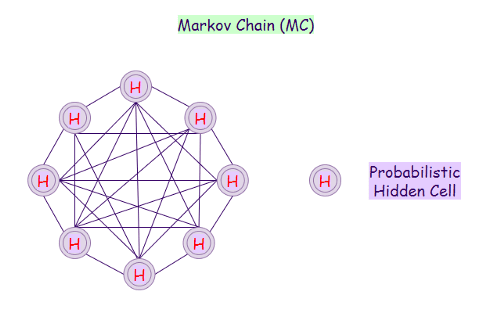
Архитектура марковских цепей
Применение марковский цепей:
Сеть Хопфилда
В нейронной сети Хопфилда (Hopfield Network, HN) каждый нейрон напрямую связан с другими нейронами. В этой сети нейрон либо включен, либо выключен. Состояние нейронов может измениться после получения сигнала от других нейронов. Обычно сети Хопфилда используется для распознавания шаблонов за счет автоассоциативной памяти. HN может распознать шаблон, даже если он несколько искажен или неполный. Если он неполный, то сеть достраивает шаблон.
Архитектура схожа с цепями Маркова. Применение сетей Хопфилда:
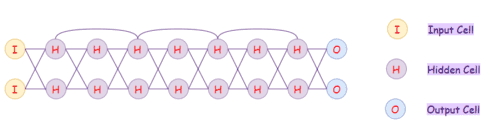
Машина Больцмана
Машина Больцмана (Boltzmann Machine) включает в себя обучение распределения вероятностей из исходного набора данных. Архитектура схожа с сетями сети Хопфилда. В машинах Больцмана есть входные и скрытые слои, как только все нейроны в скрытом слое изменяют свое состояние, входные нейроны преобразуются в выходные. Обычные машины Больцмана практически не используются для решения реальных задач, а являются основой для более сложных архитектур (RBM и DBN).
Ограниченные машин Больцмана (RBM)
Ограниченные машин Больцмана (Restricted Boltzmann Machine, RBM) — это разновидность машин Больцмана. В этой модели нейроны во входном слое и скрытом слое могут иметь симметричные связи между собой. Следует отметить, что внутри каждого слоя нет внутренних соединений (нет петель). Напротив, обычные машины Больцмана могут иметь внутренние соединения в скрытом слое. Эти ограничения позволяют эффективно обучаться (этим схожи с нейронной сетью прямого распространения).
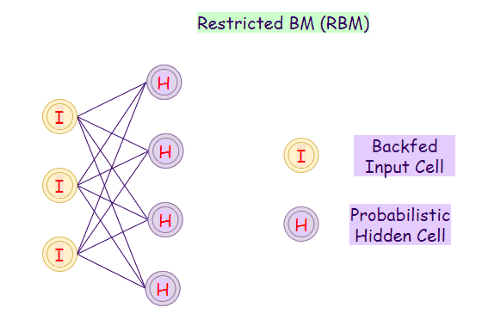
Архитектура ограниченных машин Больцмана
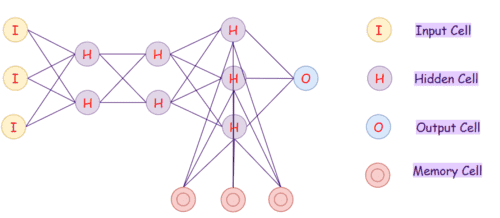
Глубокая сеть доверия (DBN)
Глубокая сеть доверия (Deep Belief Network, DBN) — это вероятностный алгоритм глубокого обучения без учителя (unsupervised learning). Слои в DBN действуют как детектор признаков. После применения обучения DBN может быть дообучена с применением обучения с учителем (supersived learning). DBN можно представить как композицию ограниченных машин Больцмана (RBM) и автоэнкодеров.
Машина неустойчивых состояний (LSM)
Машина неустойчивых состояний (Liquid State Machine, LSM) не имеет фиксированных дискретных состояний. Каждый нейрон получает входные данные от внешнего мира и других нейронов, которые могут меняться со временем. Нейроны LSM случайным образом подключаются друг к другу. Вместо функций активации используются пороговые значения. В момент, когда LSM достигают порогового значения, то определенный нейрон возбуждается и выдает выходной сигнал.
Архитектура машины неустойчивых состояний
Машина с экстремальным обучением (ELM)
В машинах с экстремальным обучениях (Extreme Learning Machine, ELM) нейроны в скрытом слое соединяются случайным образом. По архитектуре схож с LSM, но без пороговых значений. Поскольку количество соединений меньше, чем в обычных нейронных сетях, обучение ELM занимает меньше времени. Кроме того, в сетях машин с экстремальным обучением случайно назначенные веса могут не обновляться.
Архитектура машин с экстремальным обучением
Нейронные эхо-сети (ESN)

Архитектура нейронных эхо-сетей
Deep Residual Network (DRN)
Обычные глубокие нейронные сети (DNN) могут быть затратными для обучения модели и занимать много времени. Глубокие остаточные сети (DRN) справляются с этой проблемой, даже имея много слоев. В DRN результаты некоторых входных слоев переходят на следующие уровни. Эти сети могут быть довольно глубокими (они могут содержать около 300 слоев).
Архитектура глубоких остаточных сетей
Сети Кохонена
Сети Кохонена (Kohonen Networks) — это алгоритм машинного обучения без учителя, также известен как самоорганизующиеся карты. Данная сеть полезна в том случае, когда данные разбросаны по многим измерениям, а требуется получить их только в одном или двух. Поэтому сеть Кохонена также можно рассматривать как один из методов уменьшения размерности.

Архитектура сети Кохонена
Применение сетей Кохонена:
Нейронная машина Тьюринга (NTM)
Архитектура нейронной машины Тьюринга (Neural Turing Machine, NTM) состоит из двух основных компонентов: контроллер нейронной сети и сегмент памяти. В этой нейронной сети контроллер взаимодействует с внешним миром через входные и выходные векторы. Он также выполняет выборочные операции чтения и записи, взаимодействуя с матрицей памяти. Машина Тьюринга вычислительно эквивалентна современному компьютеру и расширяет возможности стандартных нейронных сетей за счет взаимодействия с внешней памятью.
Еще больше подробностей о видах нейронных сетях, их применении для решения реальных задач Data Science, вы узнаете на нашем специализированном курсе «PYNN: Введение в Нейронные сети на Python» в лицензированном учебном центре обучения и повышения квалификации Data Scientist’ов и IT-специалистов в Москве.
Restricted Boltzmann Machine.
What makes RBMs different from Boltzmann machines is that visible node isn’t connected to each other, and hidden nodes aren’t connected with each other. Other than that, RBMs are exactly the same as Boltzmann machines.
As you can see below:
· RBM is the neural network that belongs to the energy-based model
· It is a probabilistic, unsupervised, generative deep machine learning algorithm.
· RBM’s objective is to find the joint probability distribution that maximizes the log-likelihood function.
· RBM is undirected and has only two layers, Input layer, and hidden layer
· All visible nodes are connected to all the hidden nodes. RBM has two layers, visible layer or input layer and hidden layer so it is also called an asymmetrical bipartite graph.
· No intralayer connection exists between the visible nodes. There is also no intralayer connection between the hidden nodes. There are connections only between input and hidden nodes.
· The original Boltzmann machine had connections between all the nodes. Since RBM restricts the intralayer connection, it is called a Restricted Boltzmann Machine.
Since RBMs are undirected, they don’t adjust their weights through gradient descent and backpropagation. They adjust their weights through a process called contrastive divergence. At the start of this process, weights for the visible nodes are randomly generated and used to generate the hidden nodes. These hidden nodes then use the same weights to reconstruct visible nodes. The weights used to reconstruct the visible nodes are the same throughout. However, the generated nodes are not the same because they aren’t connected to each other.
Как работают машины Больцмана?
Машина Больцмана выглядит так:

Машины Больцмана являются недетерминированными (или стохастическими) порождающими моделями глубокого обучения только с двумя типами узлов -hiddenа такжеvisibleузлы. Нет выходных узлов! Это может показаться странным, но это то, что дает им эту недетерминированную особенность. У них нет типичного вывода типа 1 или 0, через который шаблоны изучаются и оптимизируются с использованием Stochastic Gradient Descent. Они учат модели без этой способности, и это делает их такими особенными!
Здесь следует отметить одно отличие, заключающееся в том, что в отличие от других традиционных сетей (A / C / R), которые не имеют каких-либо соединений между входными узлами, машина Больцмана имеет связи между входными узлами. Из изображения видно, что все узлы связаны со всеми остальными узлами независимо от того, являются ли они входными или скрытыми узлами. Это позволяет им обмениваться информацией между собой и самостоятельно генерировать последующие данные. Мы измеряем только то, что находится на видимых узлах, а не то, что на скрытых узлах. Когда ввод предоставлен, они могут захватить все параметры, шаблоны и корреляции между данными. Вот почему они называютсяDeep Generative Modelsи попасть в классUnsupervised Deep Learning,
Что такое машины Больцмана с ограничениями?
RBMs – это двухслойная искусственная нейронная сеть с генеративными возможностями. У них есть способность узнать распределение вероятностей по его набору входных данных. RBM были изобретены Джеффри Хинтоном и могут использоваться для уменьшения размерности, классификации, регрессии, совместной фильтрации, изучения особенностей и тематического моделирования.
УКР – это особый класс Машины Больцмана и они ограничены с точки зрения связей между видимыми и скрытыми единицами. Это облегчает их реализацию по сравнению с машинами Больцмана. Как указывалось ранее, они представляют собой двухслойную нейронную сеть (одна представляет собой видимый слой, а другая скрытый слой), и эти два слоя связаны полностью двудольным графом. Это означает, что каждый узел в видимом слое связан с каждым узлом в скрытом слое, но никакие два узла в одной группе не связаны друг с другом. Это ограничение допускает более эффективные алгоритмы обучения, чем те, которые доступны для общего класса машин Больцмана, в частности, Градиент основе алгоритм контрастивной дивергенции.
Ограниченная машина Больцмана выглядит следующим образом:

Как работают ограниченные машины Больцмана?
В RBM у нас есть симметричный двудольный граф, в котором нет двух единиц в одной группе. Несколько RBM также могут бытьstackedи может быть точно настроен в процессе градиентного спуска и обратного распространения. Такая сеть называется Deep Belief Network. Хотя RBM иногда используются, большинство людей в сообществе с глубоким обучением начали заменять их использование общими состязательными сетями или вариационными автоэнкодерами.
RBM – это Стохастическая Нейронная Сеть, что означает, что каждый нейрон будет иметь случайное поведение при активации. В RBM есть два других слоя единиц смещения (скрытое смещение и видимое смещение). Это то, что отличает RBM от авто-кодеров. RBM со скрытым смещением производит активацию на прямом проходе, а видимое смещение помогает RBM восстановить входные данные во время обратного прохода. Восстановленный входной сигнал всегда отличается от фактического входного сигнала, поскольку между видимыми единицами нет соединений и, следовательно, нет способа передачи информации между собой.

На изображении выше показан первый шаг в обучении RBM с несколькими входами. Входные данные умножаются на веса и затем добавляются к смещению Затем результат передается через функцию активации сигмоида, и вывод определяет, активируется ли скрытое состояние или нет. Весами будет матрица с числом входных узлов в качестве количества строк и количеством скрытых узлов в качестве количества столбцов. Первый скрытый узел получит векторное умножение входных данных, умноженное на первый столбец весов, прежде чем к нему добавится соответствующий член смещения.
И если вам интересно, что такое сигмовидная функция, вот формула:

Источник изображения: Мой блог
Таким образом, уравнение, которое мы получим на этом этапе, будет

гдеч (1)а такжеV (0)являются соответствующими векторами (матрицами столбцов) для скрытого и видимого слоев с верхним индексом в качестве итерации (v (0) означает вход, который мы предоставляем сети) иявляется вектором смещения скрытого слоя.
(Обратите внимание, что здесь мы имеем дело с векторами и матрицами, а не с одномерными значениями.)

Теперь это изображение показывает обратную фазу илиреконструкцияфаза. Это похоже на первый проход, но в противоположном направлении. Уравнение получается так:

гдеV (1)а такжеч (1)являются соответствующими векторами (матрицами столбцов) для видимого и скрытого слоев с верхним индексом в качестве итерации ибявляется вектором смещения видимого слоя.
Процесс обучения
Теперь разницаV (0) -v (1)можно рассматривать как ошибку реконструкции, которую нам нужно уменьшить на последующих этапах тренировочного процесса. Таким образом, веса корректируются на каждой итерации, чтобы минимизировать эту ошибку, и это, в сущности, и есть процесс обучения. Теперь давайте попробуем понять этот процесс в математических терминах, не углубляясь в математику. В прямом проходе мы рассчитываем вероятность выходач (1)учитывая входV (0)и весWобозначается:

и в обратном проходе, при реконструкции входа, мы рассчитываем вероятность выходаV (1)учитывая входч (1)и весWобозначается:

Веса, используемые как в прямом, так и в обратном проходе, одинаковы. Вместе эти две условные вероятности приводят нас к совместному распределению входных данных и активаций:

Реконструкция отличается от регрессии или классификации тем, что оценивает распределение вероятностей исходного ввода вместо того, чтобы связывать непрерывное / дискретное значение с примером ввода. Это означает, что он пытается угадать несколько значений одновременно. Это называется генеративным обучением, а не дискриминационным обучением, которое происходит в проблеме классификации (сопоставление входных данных с метками).
Давайте попробуем посмотреть, как алгоритм уменьшает потери или, проще говоря, как он уменьшает ошибку на каждом шаге. Предположим, что у нас есть два нормальных распределения, одно из входных данных (обозначено p (x)) и одно из восстановленного входного приближения (обозначено q (x)). Разница между этими двумя распределениями является нашей ошибкой в графическом смысле, и наша цель состоит в том, чтобы минимизировать ее, то есть максимально приблизить графики. Эта идея представлена термином под названием Расхождение Кульбака – Лейблера, KL-дивергенция измеряет неперекрывающиеся области под двумя графиками, и алгоритм оптимизации RBM пытается минимизировать эту разницу, изменяя веса так, чтобы реконструкция очень напоминала входные данные. Графики справа показывают интеграцию разности площадей кривых слева.

Изображение от Mundhenk на Wikimedia
Это дает нам интуицию о нашем сроке ошибки. Теперь, чтобы увидеть, как на самом деле это делается для RBM, нам нужно погрузиться в то, как рассчитывается потеря. Все распространенные алгоритмы обучения для RBM аппроксимируют градиент вероятности логарифма, учитывая некоторые данные, и выполняют подъем градиента в этих аппроксимациях.
Контрастное расхождение
Машины Больцмана (и УОК) являются моделями на основе энергии и конфигурации соединения, (v, ч) видимых и скрытых единиц имеет энергию, определяемую:

гдеVI, HJявляются бинарными состояниями видимой единицыяи скрытый блокj, ai, bjих предубеждения иWijэто вес между ними.
Вероятность того, что сеть назначит видимый вектор,v, дается суммированием по всем возможным скрытым векторам:

Zздесь есть функция разбиения, которая определяется суммированием всех возможных пар видимых и скрытых векторов:

Это дает нам:

Логарифмический градиент вероятности или производная логарифмической вероятности тренировочного вектора по весу удивительно просты:

где угловые скобки используются для обозначения ожиданий при распределении, указанном в нижеследующем нижнем индексе Это приводит к очень простому правилу обучения для выполнения стохастического наискорейшего подъема в логарифмической вероятности данных обучения:


Обучение работает хорошо, хотя оно лишь приблизительно приближает градиент логарифмической вероятности обучающих данных. Правило обучения гораздо ближе приближает градиент другой целевой функции, называемойКонтрастное расхождениев чем разница между двумя расхождениями Кульбака-Либлера.
Когда мы применяем это, мы получаем:

где второй член получается после каждогоКшаги отбора проб Гиббса. Вот псевдокод для алгоритма CD:
Вывод
В этом посте мы обсуждали простую архитектуру машин ограниченного Больцмана. Существует множество вариаций и улучшений RBM и алгоритмов, используемых для их обучения и оптимизации (о которых я надеюсь рассказать в следующих статьях). Я надеюсь, что это помогло вам понять и получить представление об этом удивительном генеративном алгоритме. В следующем посте мы применим RBM для создания системы рекомендаций для книг!
Не стесняйтесь исправлять любые ошибки в комментариях или предоставлять предложения для будущих сообщений! Я хотел бы написать на темы (будь то математика, приложения или упрощение), связанные с искусственным интеллектом, глубоким обучением, наукой о данных и машинным обучением.
Если вы нашли этот пост полезным, не стесняйтесь нажимать на эти сообщения! Если вы хотите посмотреть на код для реализации RBM в Python, посмотрите мой репозиторий Вот ,
Now, the difference v(0)−v(1) can be considered as the reconstruction error that we need to reduce in subsequent steps of the training process. So the weights are adjusted in each iteration so as to minimize this error and this is what the learning process essentially is. Now, let us try to understand this process in mathematical terms without going too deep into mathematics. In the forward pass, we are calculating the probability of output h(1) given the input v(0) and the weights W denoted by:
And in the backward pass, while reconstructing the input, we are calculating the probability of output v(1) given the input h(1) and the weights W denoted by:
The weights used in both the forward and the backward pass are the same. Together, these two conditional probabilities lead us to the joint distribution of inputs and the activations:
Reconstruction is different from regression or classification in that it estimates the probability distribution of the original input instead of associating a continuous/discrete value to an input example. This means it is trying to guess multiple values at the same time. This is known as generative learning as opposed to discriminative learning that happens in a classification problem (mapping input to labels).
Let us try to see how the algorithm reduces loss or simply put, how it reduces the error at each step. Assume that we have two normal distributions, one from the input data (denoted by p(x)) and one from the reconstructed input approximation (denoted by q(x)). The difference between these two distributions is our error in the graphical sense and our goal is to minimize it, i.e., bring the graphs as close as possible. This idea is represented by a term called the Kullback–Leibler divergence.
KL-divergence measures the non-overlapping areas under the two graphs and the RBM’s optimization algorithm tries to minimize this difference by changing the weights so that the reconstruction closely resembles the input. The graphs on the right-hand side show the integration of the difference in the areas of the curves on the left.
This gives us intuition about our error term. Now, to see how actually this is done for RBMs, we will have to dive into how the loss is being computed. All common training algorithms for RBMs approximate the log-likelihood gradient given some data and perform gradient ascent on these approximations.
Оглавление
Ограниченные машины Больцмана (RBM) – это нейронные сети, которые принадлежат к так называемымМодели на основе энергии, Этот тип нейронных сетей может быть не таким знакомым читателю этой статьи, как, например, нейронные сети прямой связи или свертки. Тем не менее, этот вид нейронных сетей приобрел большую популярность в последние годы в контексте Netflix Prize где RBMs достигли современного уровня производительности в совместной фильтрации и победили большую часть конкурентов.

2 Модель на основе энергии
Энергия – это термин, который не может быть связан с глубоким обучением в первую очередь. Скорее энергия является количественным свойством физики. Например. Гравитационная энергия описывает потенциальную энергию, которую тело с массой имеет по отношению к другому массивному объекту из-за гравитации. Тем не менее, некоторые архитектуры с глубоким обучением используют идею энергии в качестве метрики для измерения качества моделей.

Рис. 2. Гравитационная энергия двух масс тела.
Одной из целей моделей глубокого обучения является кодирование зависимостей между переменными. Захват зависимостей происходит посредством связывания скалярной энергии с каждой конфигурацией переменных, что служит мерой совместимости. Высокая энергия означает плохую совместимость. Модель на основе энергии всегда старается минимизировать предопределенную энергетическую функцию. Энергетическая функция для RBM определяется как:

Eq. 1. Энергетическая функция ограниченной машины Больцмана
Как можно заметить, значение энергетической функции зависит от конфигурации видимого / входного состояний, скрытых состояний, весов и смещений. Обучение RBM состоит в нахождении параметров для заданных входных значений, чтобы энергия достигала минимума.
3 Вероятностная модель
Ограниченные машины Больцмана являются вероятностными. В отличие от назначения дискретных значений модель присваивает вероятности. В каждый момент времени RBM находится в определенном состоянии. Состояние относится к значениям нейронов в видимом и скрытом слояхvа такжечас, Вероятность того, что определенное состояниеvа такжечасМожно наблюдать, дает следующее совместное распределение:

Eq. 2. Совместное распространение дляvа такжечас,
ВотZназывается «функцией разбиения», которая является суммированием по всем возможным парам видимых и скрытых векторов.
Это тот момент, когда ограниченные машины Больцмана встречаются с физикой во второй раз. Совместное распределение известно в физике как Распределение Больцмана что дает вероятность того, что частица может наблюдаться в состоянии с энергиейЕ, Как и в физике, мы назначаем вероятность наблюдать состояниеvа такжечас,это зависит от общей энергии модели. К сожалению, очень сложно рассчитать общую вероятность из-за огромного количества возможных комбинацийvа такжечасв функции разделаZ, Гораздо проще вычисление условных вероятностей состояниячасучитывая состояниеvи условные вероятности состоянияvучитывая состояниечас:

Eq. 3. Условные вероятности длячаса такжеv,
Это надо заметить заранее (прежде чем продемонстрировать этот факт на практическом примере) что каждый нейрон в RBM может существовать только в двоичном состоянии 0 или 1. Наиболее интересным фактором является вероятность того, что скрытый или видимый слойный нейрон находится в состоянии 1 – следовательно, активирован. Учитывая входной векторvвероятность одного скрытого нейронаJБыть активированным – это:

Eq. 4 Условная вероятность для одного скрытого нейрона, заданнаяv,
Вотσсигмовидная функция. Это уравнение получено путем применения правила Байеса к уравнению 3 и его большого расширения, которое здесь не рассматривается.
Аналогична вероятность, что бинарное состояние видимого нейронаяустановлен в 1:

Eq. 5. Условная вероятность для одного видимого нейрона, учитываячас,
Совместная фильтрация с ограниченными машинами Больцмана
Предположим, что некоторых людей попросили оценить набор фильмов по шкале от 1 до 5 звезд. В классическом факторном анализе каждый фильм можно объяснить с точки зрения набора скрытых факторов. Например, фильмы типаГарри Поттера такжеФорсажможет иметь сильные ассоциации со скрытыми факторамифантазияа такжедействие, С другой стороны, пользователи, которые любятИстория игрушека такжеWall-Eможет иметь сильные ассоциации со скрытымPixarфактор. УОКР используются для анализа и выяснения этих основных факторов. После нескольких эпох фазы обучения нейронная сеть видела все оценки в наборе дат обучения для каждого пользователя, умноженного на несколько раз. В это время модель должна была узнать скрытые факторы, основанные на предпочтениях пользователей и соответствующих совместных вкусов фильмов всех пользователей.
Анализ скрытых факторов выполняется в двоичном виде. Вместо того, чтобы давать модельным пользовательским рейтингам, которые продолжаются (например, 1–5 звездочек), пользователь просто говорит, понравился ли ему (рейтинг 1) конкретный фильм или нет (рейтинг 0). Двоичные значения рейтинга представляют входные данные для входного / видимого слоя. Получив входные данные, RMB затем пытается обнаружить скрытые факторы в данных, которые могут объяснить выбор фильма. Каждый скрытый нейрон представляет собой один из скрытых факторов. Учитывая большой набор данных, состоящий из тысяч фильмов, совершенно очевидно, что пользователь просмотрел и оценил только небольшое их количество. Также необходимо дать еще не оцененные фильмы, например, -1,0, так что сеть может идентифицировать фильмы без рейтинга во время обучения и игнорировать веса, связанные с ними.
Давайте рассмотрим следующий пример, где пользователю нравитсяВластелин колеца такжеГарри Поттерно не любитМатрица,Бойцовский клуба такжетитановый, Хоббит еще не видел, поэтому он получает рейтинг -1. Учитывая эти данные, машина Больцмана может выявить три скрытых факторадрама,Фантазияа такжеНаучная фантастикакоторые соответствуют жанрам фильма.

Рис. 3. Выявление скрытых факторов.
В этом примере только скрытый нейрон, который представляет жанрФантазиястановится активным. С учетом рейтингов фильма машина Restricted Boltzmann правильно распознала, что нравится пользователюФантазиябольшинство.
2 Использование скрытых факторов для прогнозирования

Рис. 4. Использование скрытых нейронов для вывода.
На рис. 4 показаны новые оценки после использования скрытых значений нейронов для вывода. Сеть определилаФантазиякак предпочтительный жанр фильма и рейтингХоббиткак фильм, который хотел бы пользователь.
В итоге процесс от обучения до прогнозирования проходит следующим образом:
Обучение Restricted Boltzmann Machine отличается от обучения регулярных нейронных сетей посредством стохастического градиентного спуска. Отклонение процедуры обучения для RBM не будет здесь рассмотрено. Вместо этого я дам краткий обзор двух основных этапов обучения и рекомендую читателю этой статьи ознакомиться с оригинальной статьей о Ограниченные машины Больцмана,
1 Выборка Гиббса

2 Контрастное расхождение
Обновление весовой матрицы происходит во времяКонтрастное расхождениешаг. векторыv_0а такжеV_kиспользуются для расчета вероятностей активации для скрытых значенийh_0а такжеh_k(Eq.4). Разница между внешние продукты из этих вероятностей с входными векторамиv_0а такжеV_kРезультаты в матрице обновления:

Eq. 6. Обновить матрицу.
Используя матрицу обновления, новые веса могут быть рассчитаны с градиентомподъем,дано:

Eq. 7. Обновите правило для весов.
Мы только что выпустили бесплатный курс по глубокому обучению!
Я основатель Академия глубокого обучения, продвинутая образовательная платформа Deep Learning. Мы предоставляем практическое современное глубокое обучение, обучение и наставничество для профессионалов и начинающих.
Среди наших вещей мы только что выпустили бесплатный вводный курс по глубокому обучению с TensorFlow, где вы можете узнать, как реализовать нейронные сети с нуля для различных сценариев использования с использованием TensorFlow.
Если вы заинтересованы в этой теме, не стесняйтесь проверить это;)

Ссылки
In an RBM, we have a symmetric bipartite graph where no two units within the same group are connected. Multiple RBMs can also be stacked and can be fine-tuned through the process of gradient descent and back-propagation. Such a network is called a Deep Belief Network. Although RBMs are occasionally used, most people in the deep-learning community have started replacing their use with General Adversarial Networks or Variational Autoencoders.
RBM is a Stochastic Neural Network which means that each neuron will have some random behavior when activated. There are two other layers of bias units (hidden bias and visible bias) in an RBM. This is what makes RBMs different from autoencoders. The hidden bias RBM produces the activation on the forward pass and the visible bias helps RBM to reconstruct the input during a backward pass. The reconstructed input is always different from the actual input as there are no connections among the visible units and therefore, no way of transferring information among themselves.
The above image shows the first step in training an RBM with multiple inputs. The inputs are multiplied by the weights and then added to the bias. The result is then passed through a sigmoid activation function and the output determines if the hidden state gets activated or not. Weights will be a matrix with the number of input nodes as the number of rows and the number of hidden nodes as the number of columns. The first hidden node will receive the vector multiplication of the inputs multiplied by the first column of weights before the corresponding bias term is added to it.
And if you are wondering what a sigmoid function is, here is the formula:
So the equation that we get in this step would be,
where h(1) and v(0) are the corresponding vectors (column matrices) for the hidden and the visible layers with the superscript as the iteration v(0) means the input that we provide to the network) and a is the hidden layer bias vector.
(Note that we are dealing with vectors and matrices here and not one-dimensional values.)
Now this image shows the reverse phase or the reconstruction phase. It is similar to the first pass but in the opposite direction. The equation comes out to be:
where v(1) and h(1) are the corresponding vectors (column matrices) for the visible and the hidden layers with the superscript as the iteration and b is the visible layer bias vector.
What is the Boltzmann Machine?
Boltzmann Machine was first invented in 1985 by Geoffrey Hinton, a professor at the University of Toronto. He is a leading figure in the deep learning community and is referred to by some as the “Godfather of Deep Learning”.
· Boltzmann Machine is a generative unsupervised model, which involves learning a probability distribution from an original dataset and using it to make inferences about never before seen data.
· Boltzmann Machine has an input layer (also referred to as the visible layer) and one or several hidden layers (also referred to as the hidden layer).
· Boltzmann Machine uses neural networks with neurons that are connected not only to other neurons in other layers but also to neurons within the same layer.
· Everything is connected to everything. Connections are bidirectional, visible neurons connected to each other and hidden neurons also connected to each other
· Boltzmann Machine doesn’t expect input data, it generates data. Neurons generate information regardless they are hidden or visible.
· For Boltzmann Machine all neurons are the same, it doesn’t discriminate between hidden and visible neurons. For Boltzmann Machine whole things are system and its generating state of the system.
The best way to think about it is through an example nuclear power plant.
· Suppose for example we have a nuclear power station and there are certain things we can measure in a nuclear power plant like the temperature of the containment building, how quickly the turbine is spinning, the pressure inside the pump, etc.
· There are lots of things we are not measuring like the speed of the wind, the moisture of the soil in this specific location, its sunny day or rainy day, etc.
· All these parameters together form a system, they all work together. All these parameters are binary. So we get a whole bunch of binary numbers that tell us something about the state of the power station.
· What we would like to do, is we want to notice that when it is going to in an unusual state. A state that is not like a normal state which we had seen before. And we don’t want to use supervised learning for that. Because we don’t want to have any examples of states that cause it to blow up.
· We would rather be able to detect that when it is going into such a state without even having seen such a state before. And we could do that by building a model of a normal state and noticing that this state is different from the normal states.
· That what Boltzmann Machine represents.
· The way this system work, we use our training data and feed into the Boltzmann Machine as input to help the system adjust its weights. It resembles our system not any nuclear power station in the world.
· It learns from the input, what are the possible connections between all these parameters, how do they influence each other and therefore it becomes a machine that represents our system.
· We can use this Boltzmann Machine to monitor our system
· Boltzmann Machine learns how the system works in its normal states through a good example.
Boltzmann Machine consists of a neural network with an input layer and one or several hidden layers. The neurons in the neural network make stochastic decisions about whether to turn on or off based on the data we feed during training and the cost function the Boltzmann Machine is trying to minimize.
By doing so, the Boltzmann Machine discovers interesting features about the data, which help model the complex underlying relationships and patterns present in the data.
This Boltzmann Machine uses neural networks with neurons that are connected not only to other neurons in other layers but also to neurons within the same layer. That makes training an unrestricted Boltzmann machine very inefficient and Boltzmann Machine had very little commercial success.
Boltzmann Machines are primarily divided into two categories: Energy-based Models (EBMs) and Restricted Boltzmann Machines (RBM). When these RBMs are stacked on top of each other, they are known as Deep Belief Networks (DBN).
Машины Больцмана с ограничениями – упрощенный

фото Израиль Паласио на Unsplash
В этом посте я попытаюсь пролить свет на интуицию об ограниченных машинах Больцмана и способах их работы. Предполагается, что это простое объяснение с небольшим количеством математики, не вдаваясь слишком глубоко в каждую концепцию или уравнение. Итак, давайте начнем с происхождения УОКР и углубимся в наше продвижение вперед.
Машины Больцмана с ограничениями (RBM) — это нелинейные обучающие функции без учителя, основанные на вероятностной модели. Признаки, извлеченные с помощью RBM или иерархии RBM, часто дают хорошие результаты при подаче в линейный классификатор, такой как линейный SVM или перцептрон.
Модель делает предположения относительно распределения входов. На данный момент scikit-learn предоставляет только данные BernoulliRBM, предполагающие, что входными данными являются либо двоичные значения, либо значения от 0 до 1, каждое из которых кодирует вероятность того, что конкретная функция будет включена.
RBM пытается максимизировать вероятность получения данных с помощью конкретной графической модели. Используемый алгоритм обучения параметрам ( стохастический максимум правдоподобия ) предотвращает отклонение представлений от входных данных, что заставляет их фиксировать интересные закономерности, но делает модель менее полезной для небольших наборов данных и, как правило, бесполезной для оценки плотности.
Метод стал популярным для инициализации глубоких нейронных сетей с весами независимых RBM. Этот метод известен как предварительное обучение без учителя.

Графическая модель и параметризация
Графическая модель RBM — это полносвязный двудольный граф.
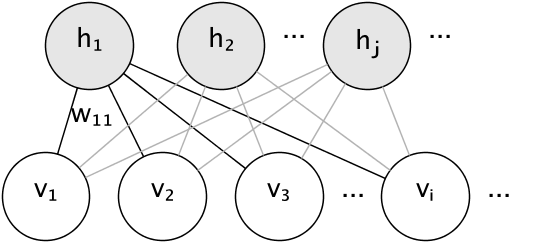
Узлы — это случайные величины, состояния которых зависят от состояния других узлов, к которым они подключены. Таким образом, модель параметризуется весами соединений, а также одним членом перехвата (смещения) для каждой видимой и скрытой единицы, опущенной на изображении для простоты.
Двудольная структура позволяет использовать для вывода эффективную блочную выборку Гиббса.
Ограниченные машины Больцмана Бернулли
В системе BernoulliRBM все единицы являются стохастическими двоичными единицами. Это означает, что входные данные должны быть либо двоичными, либо иметь действительные значения от 0 до 1, что означает вероятность того, что видимый блок будет включаться или выключаться. Это хорошая модель для распознавания символов, когда интересует, какие пиксели активны, а какие нет. Для изображений естественных сцен он больше не подходит из-за фона, глубины и тенденции соседних пикселей принимать одинаковые значения.
Стохастическое обучение с максимальным правдоподобием
Для простоты приведенное выше уравнение написано для единственного обучающего примера. Градиент относительно весов состоит из двух членов, соответствующих указанным выше. Они обычно известны как положительный градиент и отрицательный градиент из-за их соответствующих знаков. В этой реализации градиенты оцениваются по мини-сериям образцов.
При максимизации логарифма правдоподобия положительный градиент заставляет модель отдавать предпочтение скрытым состояниям, которые совместимы с наблюдаемыми обучающими данными. Благодаря двудольной структуре RBM его можно эффективно вычислить. Однако отрицательный градиент трудно преодолеть. Его цель — снизить энергию совместных состояний, которые предпочитает модель, чтобы она оставалась верной данным. Он может быть аппроксимирован цепью Маркова Монте-Карло с использованием блочной выборки Гиббса путем итеративной выборки каждого из $v$ а также $h$ дан другой, пока цепь не смешается. Образцы, полученные таким образом, иногда называют фантастическими частицами. Это неэффективно, и сложно определить, смешивается ли цепь Маркова.
Метод Contrastive Divergence предлагает остановить цепочку после небольшого количества итераций, $k$, обычно даже 1. Этот метод быстр и имеет низкую дисперсию, но выборки далеки от модельного распределения.
Устойчивая контрастная дивергенция решает эту проблему. Вместо того, чтобы запускать новую цепочку каждый раз, когда требуется градиент, и выполнять только один шаг выборки Гиббса, в PCD мы сохраняем ряд цепочек (фантазийных частиц), которые обновляются $k$ Шаги Гиббса после каждого обновления веса. Это позволяет частицам более тщательно исследовать пространство.
An Energy-Based Model.
Energy is a term that may not be associated with deep learning in the first place. Rather is energy a quantitative property of physics. E.g. gravitational energy describes the potential energy a body with mass has in relation to another massive objected due to gravity. Yet some deep learning architectures use the idea of energy as a metric for the measurement of the model’s quality.
One purpose of deep learning models is to encode dependencies between variables. The capturing of dependencies happens through associating of scalar energy to each configuration of the variables, which serves as a measure of compatibility. High energy means bad compatibility. An energy-based model tries always to minimize a predefined energy function. The energy function for the RBMs is defined as:
As can be noticed the value of the energy function depends on the configurations of visible/input states, hidden states, weights, and biases. The training of RBM consists of the finding of parameters for given input values so that the energy reaches a minimum.
Contrastive Divergence.
Boltzmann Machines (and RBMs) are Energy-based models and a joint configuration, (v,h) of the visible and hidden units has energy given by:
Where vi, hj are the binary states of visible unit ii and hidden unit j, ai, bj are their biases and wij is the weight between them.
The probability that the network assigns to a visible vector, v, is given by summing over all possible hidden vectors:
Z here is the partition function and is given by summing over all possible pairs of visible and hidden vectors:
This gives us:
The log-likelihood gradient or the derivative of the log probability of a training vector with respect to weight is surprisingly simple:
However, is much more difficult. This is because it would require us to run a Markov chain until the stationary distribution is reached (which means the energy of the distribution is minimized — equilibrium!) to approximate the second term.
So instead of doing that, we perform Gibbs Sampling from the distribution. It is a Markov Chain Monte Carlo (MC) algorithm for obtaining a sequence of observations which are approximated from a specified multivariate probability distribution when direct sampling is difficult (like in our case). The Gibbs chain is initialized with a training example v(0) of the training set and yields the sample v(k) after k steps.
Each step t consists of sampling h(t) from p(h∣v(t)) and sampling v(t+1) from p(v∣h(t)) subsequently (the value k=1 surprisingly works quite well).
The learning rule now becomes:
The learning works well even though it is only crudely approximating the gradient of the log probability of the training data. The learning rule is much more closely approximating the gradient of another objective function called the Contrastive Divergence which is the difference between two Kullback-Liebler divergences.
When we apply this, we get:
Where the second term is obtained after each k steps of Gibbs Sampling.
Here is the pseudo-code for the CD algorithm:
Recommender System
From Amazon product suggestions to Netflix movie recommendations — good recommender systems are very valuable in today’s World. And specialists who can create them are some of the top-paid Data Scientists on the planet.
Our model will be Deep Belief Networks, complex Boltzmann Machines. And you will even be able to apply it to yourself or your friends. The list of movies will be explicit so you will simply need to rate the movies you already watched, input your ratings in the dataset, execute your model and voila! The Recommender System will tell you exactly which movies you would love one night you if are out of ideas of what to watch on Netflix!
Let’s solve the problem
Part 1: Data Preprocessing
In this part, we are doing Data Preprocessing.
1.1 Import the Libraries
In this step, we import three Libraries in Data Preprocessing part. Basically, Library is a tool that you can use to make a specific job. First of all, we import the numpy library used for a multidimensional array then import the pandas library used to import the dataset. Then import torch the Pytorch library and import several packages of that. torch.nn as nn for initializing the neural network. torch.nn.parallel for parallel computations. torch.optim as optim for the optimizer. torch.utils.data for data loading and processing. autograd for implementing automatic differentiation
1.2 Import the dataset
1.3 Preparing the training set and test set
Let’s now prepare our training set and test set. Our test and training sets are tab-separated; therefore we’ll pass in the delimiter argument as . As we know very well, pandas import the data as a data frame. However, we need to convert it to an array so we can use it in PyTorch tensors. We do that using the np.array command from Numpy. We also specify that our array should be integers since we’re dealing with integer data types.
Next, we create a function that will create the matrix. The reason for doing this is to set up the dataset in a way that the RBM expects as input. We create a function called, which takes in our data as input and converts it into the matrix.
1.6 Converting the data into Torch tensors
Since we’re using PyTorch, we need to convert the data into Torch tensors. The way we do this is by using the FloatTensor utility. This will convert the dataset into PyTorch arrays.
1.7 Converting the Rating into Binary rating 1 (Liked) or 0 (Not Liked)
Part 2: Building our Model
In this Second Part, we will Build our Restricted Boltzmann Machine (RBM).
2.1 Creating the RBM Architecture
Now we need to create a class to define the architecture of the RBM. Inside the init the function we specify two parameters; the first variable is the number of visible nodes nv, and the second parameter is the number of hidden nodes nh.
Next, we initialize the weight and bias. We do this randomly using a normal distribution and using randn from the torch. The weight is of size nh and nv. We then define two types of biases. a is the probability of the hidden nodes given the visible nodes, and b is the probability of the visible nodes given the hidden nodes. In declaring them we input 1 as the first parameter, which represents the batch size.
The next step is to create a function sample_h which will sample the hidden nodes. It takes x as an argument, which represents the visible neurons.
Next, we compute the probability of h given v where h and v represent the hidden and visible nodes respectively. This represents the sigmoid activation function and is computed as the product of the vector of the weights and x plus the bias a. The product is done using the mm utility from Torch. Since we’re doing binary classification, we also return Bernoulli samples of the hidden neurons.
Next, we create a function sample_v that will sample the visible nodes. The function is similar to the sample_h function.
Now we set the number of visible nodes to the length of the training set and the number of hidden nodes to 100. The number of visible nodes corresponds to the number of features in our training set. The number of hidden nodes determines the number of features that we’d like our RBM to detect. We also set a batch size of 100 and then call the class RBM.
Part 3: Training the RBM Model
Part 4: Testing the RBM Model
Next, we test our RBM. In this stage, we use the training set data to activate the hidden neurons in order to obtain the output. This is how we get the predicted output of the test set. We then use the absolute mean to compute the test loss.
If you want dataset and code you also check my Github Profile.
Recommender System of Movies
Let us assume that some people were asked to rate a set of movies on a scale of 1–5 and each movie could be explained in terms of a set of latent factors such as drama, fantasy, action and many more. Restricted Boltzmann Machines are used to analyze and find out these underlying factors.
Using Latent Factors for Prediction
Note: If you want this article check out my academia.edu profile.
End Notes
If you liked this article, be sure to click ❤ below to recommend it and if you have any questions, leave a comment and I will do my best to answer.
That’s all folks, Have a nice day 

