
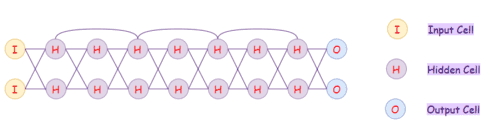
Цепь Маркова
Цепь Маркова (Markov Chain) — это математическая система, которая обрабатывает переход из одного состояния в другое на основе некоторых вероятностных правил. Вероятность перехода в какое-либо конкретное состояние зависит исключительно от текущего состояния и прошедшего времени.
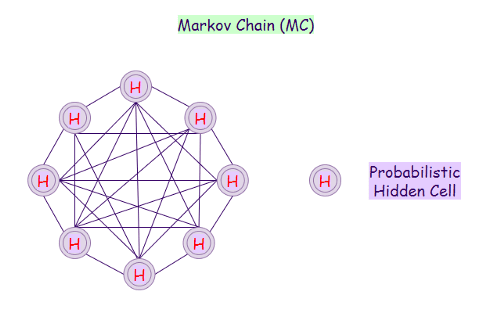
Архитектура марковских цепей
Применение марковский цепей:
Сеть Хопфилда
В нейронной сети Хопфилда (Hopfield Network, HN) каждый нейрон напрямую связан с другими нейронами. В этой сети нейрон либо включен, либо выключен. Состояние нейронов может измениться после получения сигнала от других нейронов. Обычно сети Хопфилда используется для распознавания шаблонов за счет автоассоциативной памяти. HN может распознать шаблон, даже если он несколько искажен или неполный. Если он неполный, то сеть достраивает шаблон.
Архитектура схожа с цепями Маркова. Применение сетей Хопфилда:
Машина Больцмана
Машина Больцмана (Boltzmann Machine) включает в себя обучение распределения вероятностей из исходного набора данных. Архитектура схожа с сетями сети Хопфилда. В машинах Больцмана есть входные и скрытые слои, как только все нейроны в скрытом слое изменяют свое состояние, входные нейроны преобразуются в выходные. Обычные машины Больцмана практически не используются для решения реальных задач, а являются основой для более сложных архитектур (RBM и DBN).
Ограниченные машин Больцмана (RBM)
Ограниченные машин Больцмана (Restricted Boltzmann Machine, RBM) — это разновидность машин Больцмана. В этой модели нейроны во входном слое и скрытом слое могут иметь симметричные связи между собой. Следует отметить, что внутри каждого слоя нет внутренних соединений (нет петель). Напротив, обычные машины Больцмана могут иметь внутренние соединения в скрытом слое. Эти ограничения позволяют эффективно обучаться (этим схожи с нейронной сетью прямого распространения).
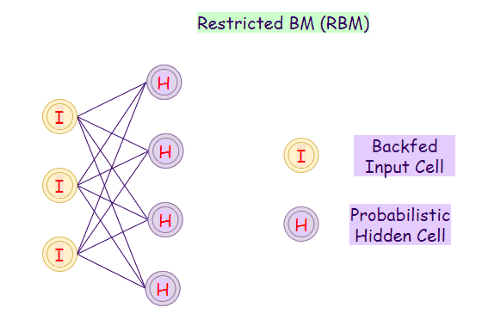
Архитектура ограниченных машин Больцмана
Глубокая сеть доверия (DBN)
Глубокая сеть доверия (Deep Belief Network, DBN) — это вероятностный алгоритм глубокого обучения без учителя (unsupervised learning). Слои в DBN действуют как детектор признаков. После применения обучения DBN может быть дообучена с применением обучения с учителем (supersived learning). DBN можно представить как композицию ограниченных машин Больцмана (RBM) и автоэнкодеров.
Машина неустойчивых состояний (LSM)
Машина неустойчивых состояний (Liquid State Machine, LSM) не имеет фиксированных дискретных состояний. Каждый нейрон получает входные данные от внешнего мира и других нейронов, которые могут меняться со временем. Нейроны LSM случайным образом подключаются друг к другу. Вместо функций активации используются пороговые значения. В момент, когда LSM достигают порогового значения, то определенный нейрон возбуждается и выдает выходной сигнал.
Архитектура машины неустойчивых состояний
Машина с экстремальным обучением (ELM)
В машинах с экстремальным обучениях (Extreme Learning Machine, ELM) нейроны в скрытом слое соединяются случайным образом. По архитектуре схож с LSM, но без пороговых значений. Поскольку количество соединений меньше, чем в обычных нейронных сетях, обучение ELM занимает меньше времени. Кроме того, в сетях машин с экстремальным обучением случайно назначенные веса могут не обновляться.
Архитектура машин с экстремальным обучением
Нейронные эхо-сети (ESN)

Архитектура нейронных эхо-сетей
Deep Residual Network (DRN)
Обычные глубокие нейронные сети (DNN) могут быть затратными для обучения модели и занимать много времени. Глубокие остаточные сети (DRN) справляются с этой проблемой, даже имея много слоев. В DRN результаты некоторых входных слоев переходят на следующие уровни. Эти сети могут быть довольно глубокими (они могут содержать около 300 слоев).
Архитектура глубоких остаточных сетей
Сети Кохонена
Сети Кохонена (Kohonen Networks) — это алгоритм машинного обучения без учителя, также известен как самоорганизующиеся карты. Данная сеть полезна в том случае, когда данные разбросаны по многим измерениям, а требуется получить их только в одном или двух. Поэтому сеть Кохонена также можно рассматривать как один из методов уменьшения размерности.

Архитектура сети Кохонена
Применение сетей Кохонена:
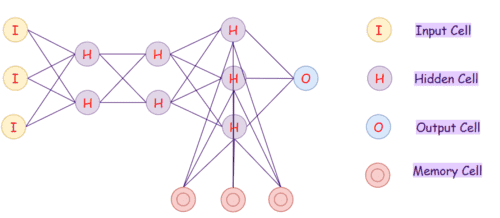
Нейронная машина Тьюринга (NTM)
Архитектура нейронной машины Тьюринга (Neural Turing Machine, NTM) состоит из двух основных компонентов: контроллер нейронной сети и сегмент памяти. В этой нейронной сети контроллер взаимодействует с внешним миром через входные и выходные векторы. Он также выполняет выборочные операции чтения и записи, взаимодействуя с матрицей памяти. Машина Тьюринга вычислительно эквивалентна современному компьютеру и расширяет возможности стандартных нейронных сетей за счет взаимодействия с внешней памятью.
Еще больше подробностей о видах нейронных сетях, их применении для решения реальных задач Data Science, вы узнаете на нашем специализированном курсе «PYNN: Введение в Нейронные сети на Python» в лицензированном учебном центре обучения и повышения квалификации Data Scientist’ов и IT-специалистов в Москве.
Перевод
Ссылка на автора
Это руководство является частью серии из двух статей о Restricted Boltzmann Machines, мощной архитектуре глубокого обучения для совместной фильтрации. В этой части я познакомлю вас с теорией ограниченных машин Больцмана. Вторая часть состоит из пошагового руководства по практической реализации модели, которая может предсказать, хочет ли пользователь фильм или нет.
Практическая часть теперь доступна Вот,

Оглавление
Ограниченные машины Больцмана (RBM) – это нейронные сети, которые принадлежат к так называемымМодели на основе энергии, Этот тип нейронных сетей может быть не таким знакомым читателю этой статьи, как, например, нейронные сети прямой связи или свертки. Тем не менее, этот вид нейронных сетей приобрел большую популярность в последние годы в контексте Netflix Prize где RBMs достигли современного уровня производительности в совместной фильтрации и победили большую часть конкурентов.
Ограниченные машины Больцмана

2 Модель на основе энергии
Энергия – это термин, который не может быть связан с глубоким обучением в первую очередь. Скорее энергия является количественным свойством физики. Например. Гравитационная энергия описывает потенциальную энергию, которую тело с массой имеет по отношению к другому массивному объекту из-за гравитации. Тем не менее, некоторые архитектуры с глубоким обучением используют идею энергии в качестве метрики для измерения качества моделей.

Рис. 2. Гравитационная энергия двух масс тела.
Одной из целей моделей глубокого обучения является кодирование зависимостей между переменными. Захват зависимостей происходит посредством связывания скалярной энергии с каждой конфигурацией переменных, что служит мерой совместимости. Высокая энергия означает плохую совместимость. Модель на основе энергии всегда старается минимизировать предопределенную энергетическую функцию. Энергетическая функция для RBM определяется как:

Eq. 1. Энергетическая функция ограниченной машины Больцмана
Как можно заметить, значение энергетической функции зависит от конфигурации видимого / входного состояний, скрытых состояний, весов и смещений. Обучение RBM состоит в нахождении параметров для заданных входных значений, чтобы энергия достигала минимума.
3 Вероятностная модель
Ограниченные машины Больцмана являются вероятностными. В отличие от назначения дискретных значений модель присваивает вероятности. В каждый момент времени RBM находится в определенном состоянии. Состояние относится к значениям нейронов в видимом и скрытом слояхvа такжечас, Вероятность того, что определенное состояниеvа такжечасМожно наблюдать, дает следующее совместное распределение:

Eq. 2. Совместное распространение дляvа такжечас,
ВотZназывается «функцией разбиения», которая является суммированием по всем возможным парам видимых и скрытых векторов.
Это тот момент, когда ограниченные машины Больцмана встречаются с физикой во второй раз. Совместное распределение известно в физике как Распределение Больцмана что дает вероятность того, что частица может наблюдаться в состоянии с энергиейЕ, Как и в физике, мы назначаем вероятность наблюдать состояниеvа такжечас,это зависит от общей энергии модели. К сожалению, очень сложно рассчитать общую вероятность из-за огромного количества возможных комбинацийvа такжечасв функции разделаZ, Гораздо проще вычисление условных вероятностей состояниячасучитывая состояниеvи условные вероятности состоянияvучитывая состояниечас:

Eq. 3. Условные вероятности длячаса такжеv,
Это надо заметить заранее (прежде чем продемонстрировать этот факт на практическом примере) что каждый нейрон в RBM может существовать только в двоичном состоянии 0 или 1. Наиболее интересным фактором является вероятность того, что скрытый или видимый слойный нейрон находится в состоянии 1 – следовательно, активирован. Учитывая входной векторvвероятность одного скрытого нейронаJБыть активированным – это:

Eq. 4 Условная вероятность для одного скрытого нейрона, заданнаяv,
Вотσсигмовидная функция. Это уравнение получено путем применения правила Байеса к уравнению 3 и его большого расширения, которое здесь не рассматривается.
Аналогична вероятность, что бинарное состояние видимого нейронаяустановлен в 1:

Eq. 5. Условная вероятность для одного видимого нейрона, учитываячас,
Совместная фильтрация с ограниченными машинами Больцмана
Предположим, что некоторых людей попросили оценить набор фильмов по шкале от 1 до 5 звезд. В классическом факторном анализе каждый фильм можно объяснить с точки зрения набора скрытых факторов. Например, фильмы типаГарри Поттера такжеФорсажможет иметь сильные ассоциации со скрытыми факторамифантазияа такжедействие, С другой стороны, пользователи, которые любятИстория игрушека такжеWall-Eможет иметь сильные ассоциации со скрытымPixarфактор. УОКР используются для анализа и выяснения этих основных факторов. После нескольких эпох фазы обучения нейронная сеть видела все оценки в наборе дат обучения для каждого пользователя, умноженного на несколько раз. В это время модель должна была узнать скрытые факторы, основанные на предпочтениях пользователей и соответствующих совместных вкусов фильмов всех пользователей.
Анализ скрытых факторов выполняется в двоичном виде. Вместо того, чтобы давать модельным пользовательским рейтингам, которые продолжаются (например, 1–5 звездочек), пользователь просто говорит, понравился ли ему (рейтинг 1) конкретный фильм или нет (рейтинг 0). Двоичные значения рейтинга представляют входные данные для входного / видимого слоя. Получив входные данные, RMB затем пытается обнаружить скрытые факторы в данных, которые могут объяснить выбор фильма. Каждый скрытый нейрон представляет собой один из скрытых факторов. Учитывая большой набор данных, состоящий из тысяч фильмов, совершенно очевидно, что пользователь просмотрел и оценил только небольшое их количество. Также необходимо дать еще не оцененные фильмы, например, -1,0, так что сеть может идентифицировать фильмы без рейтинга во время обучения и игнорировать веса, связанные с ними.
Давайте рассмотрим следующий пример, где пользователю нравитсяВластелин колеца такжеГарри Поттерно не любитМатрица,Бойцовский клуба такжетитановый, Хоббит еще не видел, поэтому он получает рейтинг -1. Учитывая эти данные, машина Больцмана может выявить три скрытых факторадрама,Фантазияа такжеНаучная фантастикакоторые соответствуют жанрам фильма.

Рис. 3. Выявление скрытых факторов.
В этом примере только скрытый нейрон, который представляет жанрФантазиястановится активным. С учетом рейтингов фильма машина Restricted Boltzmann правильно распознала, что нравится пользователюФантазиябольшинство.
2 Использование скрытых факторов для прогнозирования

Рис. 4. Использование скрытых нейронов для вывода.
На рис. 4 показаны новые оценки после использования скрытых значений нейронов для вывода. Сеть определилаФантазиякак предпочтительный жанр фильма и рейтингХоббиткак фильм, который хотел бы пользователь.
В итоге процесс от обучения до прогнозирования проходит следующим образом:
Обучение Restricted Boltzmann Machine отличается от обучения регулярных нейронных сетей посредством стохастического градиентного спуска. Отклонение процедуры обучения для RBM не будет здесь рассмотрено. Вместо этого я дам краткий обзор двух основных этапов обучения и рекомендую читателю этой статьи ознакомиться с оригинальной статьей о Ограниченные машины Больцмана,
1 Выборка Гиббса

2 Контрастное расхождение
Обновление весовой матрицы происходит во времяКонтрастное расхождениешаг. векторыv_0а такжеV_kиспользуются для расчета вероятностей активации для скрытых значенийh_0а такжеh_k(Eq.4). Разница между внешние продукты из этих вероятностей с входными векторамиv_0а такжеV_kРезультаты в матрице обновления:

Eq. 6. Обновить матрицу.
Используя матрицу обновления, новые веса могут быть рассчитаны с градиентомподъем,дано:

Eq. 7. Обновите правило для весов.
Мы только что выпустили бесплатный курс по глубокому обучению!
Я основатель Академия глубокого обучения, продвинутая образовательная платформа Deep Learning. Мы предоставляем практическое современное глубокое обучение, обучение и наставничество для профессионалов и начинающих.
Среди наших вещей мы только что выпустили бесплатный вводный курс по глубокому обучению с TensorFlow, где вы можете узнать, как реализовать нейронные сети с нуля для различных сценариев использования с использованием TensorFlow.
Если вы заинтересованы в этой теме, не стесняйтесь проверить это;)

Ссылки

фото Израиль Паласио на Unsplash
В этом посте я попытаюсь пролить свет на интуицию об ограниченных машинах Больцмана и способах их работы. Предполагается, что это простое объяснение с небольшим количеством математики, не вдаваясь слишком глубоко в каждую концепцию или уравнение. Итак, давайте начнем с происхождения УОКР и углубимся в наше продвижение вперед.
Что такое машины Больцмана?
Машины Больцмана представляют собой стохастические и генеративные нейронные сети, способные изучать внутренние представления и способные представлять и (при наличии достаточного времени) решать сложные комбинаторные задачи.
Они названы в честь Распределение Больцмана (также известный как распределение Гиббса), который является неотъемлемой частью статистической механики и помогает нам понять влияние таких параметров, как энтропия и температура, на квантовые состояния в термодинамике. Вот почему они называются моделями на основе энергии (EBM). Они были изобретены в 1985 году Джеффри Хинтоном, тогда профессором в университете Карнеги-Меллона, и Терри Сейновски, тогда профессором в университете Джона Хопкинса
Как работают машины Больцмана?
Машина Больцмана выглядит так:

Машины Больцмана являются недетерминированными (или стохастическими) порождающими моделями глубокого обучения только с двумя типами узлов -hiddenа такжеvisibleузлы. Нет выходных узлов! Это может показаться странным, но это то, что дает им эту недетерминированную особенность. У них нет типичного вывода типа 1 или 0, через который шаблоны изучаются и оптимизируются с использованием Stochastic Gradient Descent. Они учат модели без этой способности, и это делает их такими особенными!
Здесь следует отметить одно отличие, заключающееся в том, что в отличие от других традиционных сетей (A / C / R), которые не имеют каких-либо соединений между входными узлами, машина Больцмана имеет связи между входными узлами. Из изображения видно, что все узлы связаны со всеми остальными узлами независимо от того, являются ли они входными или скрытыми узлами. Это позволяет им обмениваться информацией между собой и самостоятельно генерировать последующие данные. Мы измеряем только то, что находится на видимых узлах, а не то, что на скрытых узлах. Когда ввод предоставлен, они могут захватить все параметры, шаблоны и корреляции между данными. Вот почему они называютсяDeep Generative Modelsи попасть в классUnsupervised Deep Learning,
Что такое машины Больцмана с ограничениями?
RBMs – это двухслойная искусственная нейронная сеть с генеративными возможностями. У них есть способность узнать распределение вероятностей по его набору входных данных. RBM были изобретены Джеффри Хинтоном и могут использоваться для уменьшения размерности, классификации, регрессии, совместной фильтрации, изучения особенностей и тематического моделирования.
УКР – это особый класс Машины Больцмана и они ограничены с точки зрения связей между видимыми и скрытыми единицами. Это облегчает их реализацию по сравнению с машинами Больцмана. Как указывалось ранее, они представляют собой двухслойную нейронную сеть (одна представляет собой видимый слой, а другая скрытый слой), и эти два слоя связаны полностью двудольным графом. Это означает, что каждый узел в видимом слое связан с каждым узлом в скрытом слое, но никакие два узла в одной группе не связаны друг с другом. Это ограничение допускает более эффективные алгоритмы обучения, чем те, которые доступны для общего класса машин Больцмана, в частности, Градиент основе алгоритм контрастивной дивергенции.
Ограниченная машина Больцмана выглядит следующим образом:

Как работают ограниченные машины Больцмана?
В RBM у нас есть симметричный двудольный граф, в котором нет двух единиц в одной группе. Несколько RBM также могут бытьstackedи может быть точно настроен в процессе градиентного спуска и обратного распространения. Такая сеть называется Deep Belief Network. Хотя RBM иногда используются, большинство людей в сообществе с глубоким обучением начали заменять их использование общими состязательными сетями или вариационными автоэнкодерами.
RBM – это Стохастическая Нейронная Сеть, что означает, что каждый нейрон будет иметь случайное поведение при активации. В RBM есть два других слоя единиц смещения (скрытое смещение и видимое смещение). Это то, что отличает RBM от авто-кодеров. RBM со скрытым смещением производит активацию на прямом проходе, а видимое смещение помогает RBM восстановить входные данные во время обратного прохода. Восстановленный входной сигнал всегда отличается от фактического входного сигнала, поскольку между видимыми единицами нет соединений и, следовательно, нет способа передачи информации между собой.

На изображении выше показан первый шаг в обучении RBM с несколькими входами. Входные данные умножаются на веса и затем добавляются к смещению Затем результат передается через функцию активации сигмоида, и вывод определяет, активируется ли скрытое состояние или нет. Весами будет матрица с числом входных узлов в качестве количества строк и количеством скрытых узлов в качестве количества столбцов. Первый скрытый узел получит векторное умножение входных данных, умноженное на первый столбец весов, прежде чем к нему добавится соответствующий член смещения.
И если вам интересно, что такое сигмовидная функция, вот формула:

Источник изображения: Мой блог
Таким образом, уравнение, которое мы получим на этом этапе, будет

гдеч (1)а такжеV (0)являются соответствующими векторами (матрицами столбцов) для скрытого и видимого слоев с верхним индексом в качестве итерации (v (0) означает вход, который мы предоставляем сети) иявляется вектором смещения скрытого слоя.
(Обратите внимание, что здесь мы имеем дело с векторами и матрицами, а не с одномерными значениями.)

Теперь это изображение показывает обратную фазу илиреконструкцияфаза. Это похоже на первый проход, но в противоположном направлении. Уравнение получается так:

гдеV (1)а такжеч (1)являются соответствующими векторами (матрицами столбцов) для видимого и скрытого слоев с верхним индексом в качестве итерации ибявляется вектором смещения видимого слоя.
Процесс обучения
Теперь разницаV (0) -v (1)можно рассматривать как ошибку реконструкции, которую нам нужно уменьшить на последующих этапах тренировочного процесса. Таким образом, веса корректируются на каждой итерации, чтобы минимизировать эту ошибку, и это, в сущности, и есть процесс обучения. Теперь давайте попробуем понять этот процесс в математических терминах, не углубляясь в математику. В прямом проходе мы рассчитываем вероятность выходач (1)учитывая входV (0)и весWобозначается:

и в обратном проходе, при реконструкции входа, мы рассчитываем вероятность выходаV (1)учитывая входч (1)и весWобозначается:

Веса, используемые как в прямом, так и в обратном проходе, одинаковы. Вместе эти две условные вероятности приводят нас к совместному распределению входных данных и активаций:

Реконструкция отличается от регрессии или классификации тем, что оценивает распределение вероятностей исходного ввода вместо того, чтобы связывать непрерывное / дискретное значение с примером ввода. Это означает, что он пытается угадать несколько значений одновременно. Это называется генеративным обучением, а не дискриминационным обучением, которое происходит в проблеме классификации (сопоставление входных данных с метками).
Давайте попробуем посмотреть, как алгоритм уменьшает потери или, проще говоря, как он уменьшает ошибку на каждом шаге. Предположим, что у нас есть два нормальных распределения, одно из входных данных (обозначено p (x)) и одно из восстановленного входного приближения (обозначено q (x)). Разница между этими двумя распределениями является нашей ошибкой в графическом смысле, и наша цель состоит в том, чтобы минимизировать ее, то есть максимально приблизить графики. Эта идея представлена термином под названием Расхождение Кульбака – Лейблера, KL-дивергенция измеряет неперекрывающиеся области под двумя графиками, и алгоритм оптимизации RBM пытается минимизировать эту разницу, изменяя веса так, чтобы реконструкция очень напоминала входные данные. Графики справа показывают интеграцию разности площадей кривых слева.

Изображение от Mundhenk на Wikimedia
Это дает нам интуицию о нашем сроке ошибки. Теперь, чтобы увидеть, как на самом деле это делается для RBM, нам нужно погрузиться в то, как рассчитывается потеря. Все распространенные алгоритмы обучения для RBM аппроксимируют градиент вероятности логарифма, учитывая некоторые данные, и выполняют подъем градиента в этих аппроксимациях.
Машины Больцмана (и УОК) являются моделями на основе энергии и конфигурации соединения, (v, ч) видимых и скрытых единиц имеет энергию, определяемую:

гдеVI, HJявляются бинарными состояниями видимой единицыяи скрытый блокj, ai, bjих предубеждения иWijэто вес между ними.
Вероятность того, что сеть назначит видимый вектор,v, дается суммированием по всем возможным скрытым векторам:

Zздесь есть функция разбиения, которая определяется суммированием всех возможных пар видимых и скрытых векторов:

Это дает нам:

Логарифмический градиент вероятности или производная логарифмической вероятности тренировочного вектора по весу удивительно просты:

где угловые скобки используются для обозначения ожиданий при распределении, указанном в нижеследующем нижнем индексе Это приводит к очень простому правилу обучения для выполнения стохастического наискорейшего подъема в логарифмической вероятности данных обучения:


Обучение работает хорошо, хотя оно лишь приблизительно приближает градиент логарифмической вероятности обучающих данных. Правило обучения гораздо ближе приближает градиент другой целевой функции, называемойКонтрастное расхождениев чем разница между двумя расхождениями Кульбака-Либлера.
Когда мы применяем это, мы получаем:

где второй член получается после каждогоКшаги отбора проб Гиббса. Вот псевдокод для алгоритма CD:
Вывод
В этом посте мы обсуждали простую архитектуру машин ограниченного Больцмана. Существует множество вариаций и улучшений RBM и алгоритмов, используемых для их обучения и оптимизации (о которых я надеюсь рассказать в следующих статьях). Я надеюсь, что это помогло вам понять и получить представление об этом удивительном генеративном алгоритме. В следующем посте мы применим RBM для создания системы рекомендаций для книг!
Не стесняйтесь исправлять любые ошибки в комментариях или предоставлять предложения для будущих сообщений! Я хотел бы написать на темы (будь то математика, приложения или упрощение), связанные с искусственным интеллектом, глубоким обучением, наукой о данных и машинным обучением.
Если вы нашли этот пост полезным, не стесняйтесь нажимать на эти сообщения! Если вы хотите посмотреть на код для реализации RBM в Python, посмотрите мой репозиторий Вот ,
Нейронные квантовые состояния

Фото By Татьяна Шепелева /shutterstock.com
Одной из самых сложных проблем современной теоретической физики является так называемая проблема многих тел, Типичные системы многих тел состоят из большого количества сильно взаимодействующих частиц. Немногие такие системы поддаются точной математической обработке, и для достижения прогресса необходимы численные методы. Однако, поскольку ресурсы, необходимые для задания общего квантового состояния многих тел, экспоненциально зависят от числа частиц в системе (точнее, от числа степеней свободы), даже лучшим современным суперкомпьютерам сегодня не хватает мощности дляв точкукодировать такие состояния (они могут обрабатывать только относительно небольшие системы, содержащие менее ~ 45 частиц).
Как мы увидим, недавнее применение методов машинного обучения (в частности, искусственных нейронных сетей), как было показано, обеспечивает высокоэффективное представление таких сложных состояний, делая их подавляющую сложность вычислительно управляемой.
В этой статье я расскажу, как применить (тип) искусственную нейронную сеть для представления квантовых состояний многих частиц. Статья будет разделена на три части:
Преамбула
Есть увлекательная история изложенный одним из Альберт Эйнштейн Научные сотрудники, польский физик Леопольд Инфельд, в его автобиография,

Эйнштейн и Инфельд в доме Эйнштейна (источник).
По словам Инфельда, после того, как два физика провели несколько месяцев, выполняя долгие и изнурительные вычисления, Эйнштейн сделал бы следующее замечание:
– Эйнштейн (1942).
Эйнштейн имел в виду, что в то время как люди должны прибегать к сложным вычислениям и символическим рассуждениям для решения сложных физических проблем,Природе не нужно.
Быстрая заметкаЭйнштейн использовал здесь термин «интегрировать», потому что многие физические теории формулируются с использованием уравнений, называемых «дифференциальными уравнениями», и для поиска решений таких уравнений необходимо применять процесс «интегрирования».
Проблема многих тел
Как отмечалось во введении, общеизвестно трудной проблемой теоретической физики является проблема многих тел, Эта проблема очень долго исследовалась в обеих классических системах (физических системах, основанных на Три закона движения Ньютона и его уточнения) и квантовые системы (системы, основанные на соблюдении законов квантовой механики).
Первой (классической) проблемой многих тел, которая была тщательно изучена, была проблема трех тел, включающая Землю, Луну и Солнце.
Простая орбита системы из трех тел с равными массами (источник).
Одним из первых ученых, которые напали на эту проблему многих тел, был никто иной, как Исаак Ньютон в своем шедевре Principia Mathematica:
Исаак Ньютон (1687)

Ньютона Principia Mathematica , пожалуй, самая важная научная книга в истории.
Поскольку по существувсесоответствующие физические системы состоят из совокупности взаимодействующих частиц, проблема многих тел чрезвычайно важна.
Определение бедного человека
Можно определять проблема как «изучение влияния взаимодействий между телами на поведение системы многих тел».

Столкновения ионов золота генерируют кварк-глюонную плазму, типичную систему многих тел (источник).
Значение «многие» в этом контексте может быть от трех до бесконечности. В недавняя статья, мы с коллегами показали, что сигнатуры квантового поведения многих тел можно найти уже дляN= 5 спиновых возбуждений (рисунок ниже).

Плотность состояний типа спиновой системы (модель XX). При увеличении числа спиновых возбуждений от 2 до 5 приближается гауссово распределение (типичное для систем многих тел с двухчастичными связями) (источник).
В настоящей статье я остановлюсь на квантпроблема многих тел который был моя основная тема исследований поскольку 2013,
Квантовые системы многих тел
Сложность квантовых систем многих тел была определена физиками уже в 1930-х годах Примерно в то же время, великий физик Пол Дирак Предусматриваемый две основные проблемы в квантовой механике.

Английский физик Поль Дирак (источник).
К счастью, квантовые состояния многих физических систем могут быть описаны с использованием гораздо меньшего количества информации, чем максимальная емкость их гильбертовых пространств. Этот факт используется несколькими численными методами, включая хорошо известные Квант Монте-Карло (QMC) метод.
Квантовые волновые функции
Проще говоря, квантовая волновая функция математически описывает состояние квантовой системы. Первая квантовая система для получить точное математическое лечение был атом водорода.

Вероятность нахождения электрона в атоме водорода (представлена яркостью) (источник).
В общем случае квантовое состояние представлено комплексной амплитудой вероятности Ψ (S) где аргументSсодержит всю информацию о состоянии системы. Например, в цепочке спин-1/2:


1D спиновая цепь: каждая частица имеет значение σ по оси z (источник).
От Ψ (S), вероятности, связанные с измерениями, выполненными в системе, могут быть получены. Например, квадратный модуль Ψ (S), положительное действительное число, дает распределение вероятностей, связанное с Ψ (S):

Гамильтонов оператор
Свойства квантовой системы инкапсулированы Гамильтонов оператор ЧАС, Последний является суммой двух слагаемых:
Допустимые уровни энергии квантовой системы (ее энергетический спектр) могут быть получены путем решения так называемой Уравнение Шредингера уравнение в частных производных, которое описывает поведение квантово-механических систем.

Австрийский физик Эрвин Шредингер, один из отцов квантовой механики (источник).
Независимая от времени версия уравнения Шредингера задается следующей системой собственных значений:

Собственные значения и соответствующие собственные состояния

Самая низкая энергия соответствует так называемому «основному состоянию» системы.
Простой пример
Для конкретности рассмотрим следующий пример: генератор квантовых гармоник, QHO является квантово-механическим аналогом классического гармонического осциллятора (см. Рисунок ниже), который представляет собой систему, которая испытывает силу при смещении от своей начальной точки, которая восстанавливает ее в ее положение равновесия.
Массово-пружинный гармонический осциллятор (источник)
анимация ниже сравнивает классическую и квантовую концепции простого гармонического осциллятора.
Волновая функция, описывающая генератор квантовых гармоник (Wiki).
В то время как простая колеблющаяся масса в четко определенной траектории представляет классическую систему (блоки A и B на рисунке выше), соответствующая квантовая система представлена сложной волновой функцией. В каждом блоке (начиная с C) есть две кривые: синяя – это действительная часть Ψ, а красная – мнимая часть.
Вид квантовых спин-систем с высоты птичьего полета
В квантовой механике вращение можно грубо понимать как «внутреннюю форму углового момента», которую несут частицы и ядра. Хотя вращение частицы вокруг своей оси является интуитивно понятным, эта картина не совсем верна, поскольку тогда частица будет вращаться со скоростью, превышающей скорость света, что нарушит фундаментальные физические принципы. Если спины факта являются квантово-механическими объектами без классического аналога.

Пример системы многих тел: спиновая примесь, распространяющаяся по цепочке атомов (источник)
Квантовые спиновые системы тесно связаны с явлениями магнетизм, Магниты сделаны из атомов, которые часто являются маленькими магнитами. Когда эти атомные магниты становятся параллельно ориентированными, они дают начало знакомому нам макроскопическому эффекту.

Магнитные материалы часто показывают спиновые волны, распространяющиеся возмущения в магнитном порядке (источник).
Сейчас я кратко изложу основные компоненты алгоритмов машинного обучения, которые помогут читателю понять их связь с квантовыми системами.
Машинное обучение = Машина + Обучение
Подходы машинного обучения имеют два основных компонента (Карлео, 2017):


Два компонента машинного обучения (NN мультфильм из Вот).
Нейронные сети
Искусственные нейронные сети обычно являются нелинейными многомерными вложенными функциями. Их внутренняя работа понятна только эвристически, и исследование их структуры не дает понимания относительно функции, которую она приближает.

Простая искусственная нейронная сеть с двумя скрытыми слоями (источник).
Из-за отсутствия четкой связи между параметрами сети и математической функцией, которая аппроксимируется, ANN часто называют «черными ящиками».
Сила аппроксимации нейронных сетей (с кодами Python)Почему нейронные сети могут предсказать результаты (почти) любого процессаtowardsdatascience.comСвязи между нейронными сетями и чистой математикойКак эзотерическая теорема дает важные подсказки о силе искусственных нейронных сетейmedium.freecodecamp.org
Существует несколько типов ИНС, но для нашей нынешней цели я остановлюсь на конкретном случае машин Больцмана с ограничениями (RBM).
Ограниченные машины Больцмана являются генеративными стохастическими нейронными сетями. У них много приложений, в том числе:
RBMs относятся к классу моделей, известных как Модели на основе энергии, Они отличаются от других (более популярных) нейронных сетей, которые оцениваютценностьна основе входных данных при оценке RBMплотности вероятностейвходов (они оценивают много точек вместо одного значения).
У RBM есть следующие свойства:
Энергетический функционал, который нужно минимизировать, определяется как:

Уравнение 1: Функциональность энергии минимизирована с помощью RBM.
Совместное распределение вероятностей как видимых, так и скрытых единиц гласит:

Уравнение 2: Общее распределение вероятностей.
где нормализация постояннаяZназывается функция разделения, Отслеживая скрытые единицы, мы получаем предельную вероятность видимого (входного) вектора:

Eq.3: входные единицы распределения предельной вероятности,
Поскольку, как отмечалось ранее, активация скрытого (видимого) объекта является взаимно независимой, учитывая активацию видимого (скрытого) объекта, можно написать:

Ур.4: Условные вероятности становятся продуктами из-за взаимной независимости.

Eq. 5: То же, что и уравнение 4.
Наконец, вероятности активации гласят:

Уравнение 6: Вероятности активации.
Этапы обучения являются следующий:

Как RBMs обрабатывают входные данные, простой пример
Следующий анализ в значительной степени основан на этом отличный учебник, Три рисунка ниже показывают, как RBM обрабатывает входные данные.

Простая RBM обработка входов (источник).
Как УОК учатся восстанавливать данные
RBMs выполняют неконтролируемый процесс, называемый «реконструкцией». Они учатся восстанавливать данные, выполняя длинную последовательность проходов (прямого и обратного) между двумя уровнями. При обратном проходе, как показано на диаграмме ниже, функции активации узлов в скрытом слое становятся новыми входными данными.

Произведение этих входных данных и соответствующие веса суммируются и новые смещениябиз видимого слоя добавляются на каждом входном узле. Новый вывод таких операций называется «реконструкцией», потому что он является приближением к исходному вводу.
Естественно, что реконструкции и исходные данные вначале сильно различаются (поскольку значениявесслучайно инициализируются). Однако, поскольку ошибка неоднократно распространялась обратно по отношению квесс, это постепенно сводится к минимуму.
Поэтому мы видим, что:
Объединяя оба условных распределения, совместное распределение вероятностейИкса такжеполучается, то есть RBM изучает, как аппроксимировать исходные данные (структуру входных данных).
Как соединить машинное обучение и квантовые системы?
В недавняя статья опубликовано в журнале Science, было предложено рассматривать квантовую волновую функцию Ψ (S) квантовой системы многих тел в виде черного ящика, а затем аппроксимируйте ее, используя RBM. УКР обучен представлять Ψ (Sчерез оптимизацию его параметров.

RBM используется Карлео и Тройер (2017) который кодирует спиновое квантовое состояние многих тел.
Вопрос состоит в том, как переформулировать (не зависящее от времени) уравнение Шредингера, которое является проблемой собственных значений, как проблему машинного обучения.
Вариационные методы
Как выясняется, ответ известен уже довольно давно, и в его основе лежит так называемая вариационный метод альтернативная формулировка волнового уравнения, которая может быть использована для получения энергий квантовой системы. Используя этот метод, мы можем написать задачу оптимизации следующим образом:

Квантовые состояния и ограниченные машины Больцмана
В Карлео и Тройер (2017) RBM используются для представления квантового состояния Ψ (S). Они обобщают RBM для учета сложных сетевых параметров.
Легко показать, что функционал энергии можно записать в виде

где аргумент значения ожидания после последнего знака равенства является локальной энергией. Затем нейронная сеть обучается с использованием метода Стохастическая реконфигурация (СР). Соответствующая итерация оптимизации гласит:

Протокол обновления градиентного спуска.
гдеηэто скорость обучения иSэто стохастическая матрица реконфигурации который зависит от собственных состояний и их логарифмических производных. Для более подробной информации проверьте Эта бумага,
Карлео и Тройер (2017) особенно интересовались квантовыми системами со спином 1/2, и они записывают квантовое состояние следующим образом:

В этом выраженииWАргументом set является набор параметров:

где компоненты наа такжебреальны, ноWможет быть сложным. Отсутствие внутрислойных взаимодействий, типичное для архитектуры RBM, позволяет скрытым переменным проходить (или прослеживаться), что значительно упрощает приведенное выше выражение для:

Для обучения квантовых волновых функций следует аналогичная процедура как описано выше для RBM (более подробно Вот).
Впечатляющая Точность
На рисунке ниже показана незначительная относительная погрешность оценки энергии основного состояния СКО. Каждый график соответствует тесту, представляющему собой систему с известными точными решениями. Горизонтальная ось представляет собой плотность скрытых единиц, то есть соотношение между количеством скрытых и видимых единиц. Обратите внимание, что даже при относительно небольшом количестве скрытых единиц точность модели уже впечатляет (одна часть на миллион ошибок!)

Погрешность модели основного состояния энергии относительно точного значения в трех тестовых случаях (источник)
В этой короткой статье мы увидели, что Restricted Boltzmann Machines (RBMs), простой тип искусственной нейронной сети, можно использовать для чрезвычайно высокой точности расчета энергии основного состояния квантовых систем многих частиц. Для более подробной информации, я предлагаю проверить отличная бумага который первым предложил этот подход.
Спасибо за чтение!
мой Github и мой личный сайт www.marcotavora.me (надеюсь) есть еще кое-что интересное о науке о данных и физике.
Как всегда, конструктивная критика и отзывы приветствуются!
Машина
Больцмана — вид стохастической
рекуррентной нейронной сети, изобретенной
Джеффри Хинтоном и Терри Сейновски в
1985 году. Машина Больцмана может
рассматриваться как стохастический
генеративный вариант сети Хопфилда.
Эта
сеть использует для обучения алгоритм
имитации отжига и оказалась первой
нейронной сетью, способной обучаться
внутренним представлениям, решать
сложные комбинаторные задачи. Несмотря
на это, из-за ряда проблем, машины
Больцмана с неограниченной связностью
не могут использоваться для решения
практических проблем. Если же связность
ограничена, то обучение может быть
достаточно эффективным для использования
на практике. В частности, из каскада
ограниченных машин Больцмана строится
так называемая deep belief network.
Стохастические
(теоретико-вероятностные) модели
используются для отображения вероятностных
процессов и событий. В этом случае
анализируется ряд реализаций случайного
процесса, и оцениваются средние
характеристики. В стохастических моделях
значения входных параметров (переменных)
известны лишь с определенной степенью
вероятности, т.е. эти параметры являются
стохастическими; соответственно,
случайным будет и процесс эволюции
системы.
Например,
модель, описывающая изменение температуры
воздуха в течение года. Точно предсказать
температуру воздуха не будущий период
невозможно, задается только диапазон
изменения температуры и вероятность
того, что истинная температура воздуха
попадет в этот диапазон.
Стохастические
модели применяется для исследования
системы, состояние которой зависит не
только от контролируемых, но и от
неконтролируемых воздействий или в ней
самой есть источник случайности. К
стохастическим системам относятся все
системы, которые включают человека,
например, заводы, аэропорты, вычислительные
системы и сети, магазины, предприятия
бытового обслуживания и т.п.
Одним
из основных недостатков сети Хопфилда
является тенденция «стабилизации»
состояния сети в локальном, а не в
глобальном минимуме. Практически
желательно, чтобы сеть переходила в
глубокие минимумы энергии чаще, чем
неглубокие, и чтобы относительная
вероятность перехода сети в один из
двух минимумов с разной энергией зависела
только от соотношения их глубин. Это
позволило бы управлять вероятностями
получения конкретных выходных векторов
состояния путём изменения профиля
энергетической поверхности системы за
счет модификации весов связей. На основе
этих соображений и построена машина
Больцмана.
Идея
использования «теплового шума» для
выхода из локальных минимумов и повышения
вероятности попадания в более глубокие
минимумы принадлежит С. Кирпатрику. На
основе этой идеи разработан алгоритм
имитации отжига.
Введем
некоторый параметр t — аналог уровня
теплового шума. Тогда вероятность
активности некоторого нейрона к
определяется на основе вероятностной
функции Больцмана:

где
t — уровень теплового шума в сети; E_k —
сумма весов связей к-го нейрона со всеми
активными в данный момент нейронами.
Метод
имитации отжига представляет собой
алгоритмический аналог физического
процесса управляемого охлаждения. Это
метод позволяет находить глобальный
минимум функции нескольких переменных.
Классический
алгоритм имитации отжига.
В
машине Больцмана имитационный отжиг
имитируется путем вероятностного
механизма перехода нейрона в новое
состояние.
где
∆Ei – изменение энергии i-го нейрона;
S
–состояние нейрона в момент времени
t+1.
Если
начать процесс релаксации с высокой
температуры и постепенно снижать ее,
то система придет в состояние равновесия.
Sources:
Стохастические
модели,
Сети
Больцмана 1,
Сети
Больцмана 2,
лекция 8
Соседние файлы в предмете Государственный экзамен

