
Для просмотра базового индекса компьютера
Несмотря на то что, начиная с 8 версии, служебная программа оценки производительности утратила свою актуальность, для пользователей она может иметь вескую значимость при анализе отдельных компонентов.
В Windows 10 стандартная служебная программа индекса производительности изменила расположение и потеряла графический интерфейс, однако это не мешает проанализировать систему на производительность посредством консолей и стороннего программного обеспечения.
Проверка индекса производительности с помощью командной строки
Одним из стандартных способов проверки оценки производительности в Windows 10 выступает командная строка (консоль, терминал). Командная строка – это программа, позволяющая управлять компьютером посредством ввода текстовых команд.
Для того чтобы проанализировать имеющиеся системные компоненты на производительность с помощью командной строки, необходимо открыть ее путем поиска – комбинацией клавиш «WIN + R».
Перед нами откроется служба «Выполнить», которая позволит совершить быстрый поиск нужной нам программы.
Для запуска командной строки в поле «Открыть» пишем запрос «cmd» и нажимаем «ОК».
Как базы данных создают индексы

Неиндексированная и индексированная базы данных
Индексирование базы данных обычно выполняется при помощи алгоритма, определяющего, как должен создаваться и храниться индекс. Конкретный процесс создания индекса может варьироваться в зависимости от типа используемой системы базы данных, однако в целом общие этапы выглядят так:
Создание индекса может существенно улучшить производительность запросов к базе данных и операций поиска, поскольку оно позволяет системе базы данных находить соответствующие записи быстрее и эффективнее. Однако индексирование также может обладать и недостатками, например, увеличение требований к объёму хранилища и замедление выполнения операций вставки и обновления, поэтому перед созданием индекса следует взвесить плюсы и минусы.
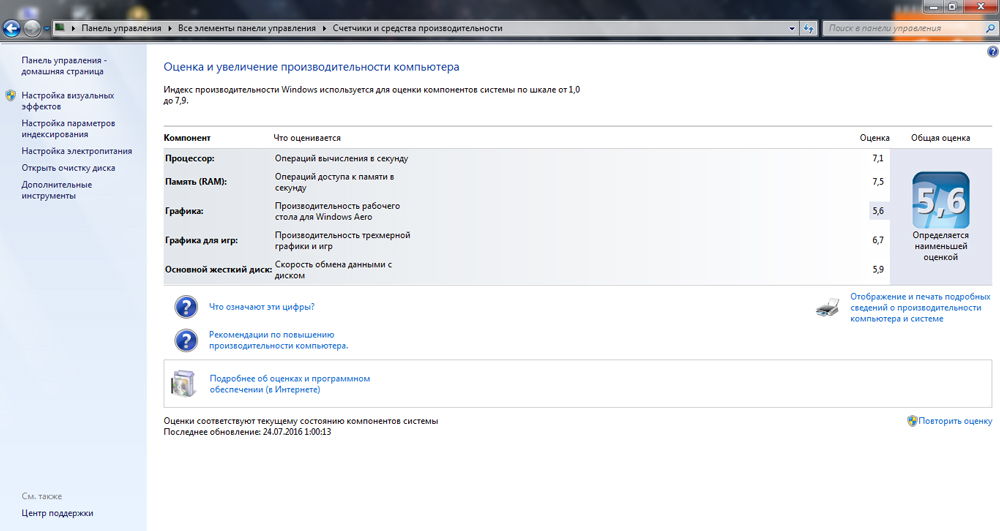
Индекс производительности Windows 10
Индекс производительности – это служебная программа операционной системы, которая позволяет диагностировать компоненты компьютера, отвечающие за его работу. Программа с целью определения быстродействия проводит анализ и тестирование составляющих компонентов системы на их взаимодействие с программным обеспечением, в результате чего показывает условное значение производительности компьютера. Минимальное значение, начиная с операционной системы Windows 8, составляет 1,0 балла, максимальное – 9,9.
Поиск
Для облегчения описания приведу скриншот итогового результата

Полнотекст
Основным типом запроса у нас служит Simple Query String Query:
где .exact — это поля, проиндексированные default анализатором. Важность имени документа считаем в два раза выше остальных полей. Сочетание “default_operator”: “or” и “minimum_should_match”: “-35%” позволяет находить документы в которых нет до 35% искомых слов.
Синонимы
Вообще для индексирования и поиска используются разные анализаторы, но единственное отличие в них — это добавление фильтра для подмешивания синонимов в поисковый запрос:
Учёт прав
Для поиска с учетом прав основной запрос вложен в Bool Query, с добавлением фильтра:
Как помним из раздела про индексацию, в индексе есть поле с ИД пользователей и групп, имеющих права на документ. Если есть пересечение этого поля с переданным массивом — значит есть и права.
Тюнинг релевантности
По умолчанию Elasticsearch оценивает релевантность результатов по алгоритму BM25, используя запрос и текст документа. Мы решили, что на оценку соответствия желаемого и фактического результата должны влиять ещё три фактора:

Внешний интеллект
Для части функциональности умного поиска нам необходимо извлечь из поискового запроса различные факты: даты с указанием их применения (создания, изменения, утверждения и т.п.), названия организаций, виды искомых документов и т.п.
Также желательно классифицировать запрос в определённую категорию, например, документы по организациям, по сотрудникам, нормативные и т.п.
Эти две операции выполняются интеллектуальным модулем ECM — DIRECTUM Ario.
Процесс умного поиска
Настало время подробнее рассмотреть, какими механизмами реализуются элементы интеллектуальности.
Исправление ошибок пользователя
Определение правильности раскладки происходит на основе триграмной модели языка — для строки вычисляется, насколько вероятно встретить её трехсимвольные последовательности в текстах на английском и русском языках. Если текущая раскладка считается менее вероятной, то, во-первых, показывается подсказка с исправленной раскладкой:

а во-вторых, дальнейшие этапы поиска выполняются с исправленной раскладкой:

И уж если с исправленной раскладкой ничего не найдётся, то поиск запускается с оригинальной строкой.
Исправление опечаток реализовано с помощью Phrase Suggester. С ним есть проблема — если выполнить запрос на нескольких индексах одновременно, то suggest может ничего не вернуть, в то время как при выполнении только на одном индексе результаты есть. Это лечится установкой confidence = 0, но тогда suggest предлагает заменять слова на их нормальную форму. Согласитесь, странно будет при поиске “письма” получить ответ в духе: Возможно, вы искали письмо?
Это можно обойти, используя сразу два suggester’а в запросе:
Из общих параметров используются
“confidence”: 0.0,
“max_errors”: 3.0,
“size”: 1
Если первый suggester вернул результат, а второй нет, значит этот результат — сама исходная строка, возможно со словами в других формах, и подсказку показывать не надо. В случае, если подсказка всё-таки требуется, исходная поисковая фраза сливается с подсказкой. Это происходит путем замены только исправленных слов и только тех, которые проверка орфографии (используем Hunspell) сочтёт некорректными.
Если поиск по исходной строке вернул 0 результатов, то он заменяется полученной слиянием строкой и снова выполняется поиск:

Иначе полученная строка с подсказками возвращается только в качестве подсказки для поиска:

Классификация запросов и извлечение фактов
Как я уже упоминал, мы используем DIRECTUM Ario, а именно сервис классификации текстов и сервис извлечения фактов. Для этого мы отдали аналитикам обезличенные поисковые запросы и список фактов, которые нам интересны. На основе запросов и знаний о том, какие документы есть в системе, аналитики выделили несколько категорий и обучили сервис классификации определять категорию по тексту запроса. Исходя из получившихся категорий и списка фактов, сформулировали правила использования этих фактов. Например, фраза за прошлый год в категории Все считается датой создания документа, а в категории По организации — датой регистрации. При этом созданные в прошлом году должно в любой категории попадать в дату создания.
Со стороны поиска — сделали конфиг, в котором прописали категории, какие факты в какие фасетные фильтры применяются.
Автодополнение ввода
Кроме уже упоминавшегося исправления раскладки, в автодополнение попадают прошлые поисковые запросы пользователя и общедоступные документы.

Они реализованы с помощью другого вида Suggester’ов — Completion Suggester, но у каждого есть свои нюансы.
История поисков
Пользователей в ECM гораздо меньше, чем у поисковых систем, и выделить для них достаточное количество общих запросов почему ленин гриб не представляется возможным. Показывать всё подряд тоже не стоит из-за соображений приватности. Обычный Completion Suggester умеет искать только по всему набору документов в индексе, но к нему на помощь приходит Context Suggester — способ задать для каждой подсказки некий контекст и при поиске фильтровать по этим контекстам. Если в качестве контекстов использовать имена пользователей, то каждому можно показывать только его историю.
Также нужно дать пользователю возможность удалить подсказку, за которую ему стыдно. В качестве ключа для удаления мы использовали имя пользователя и текст подсказки. В результате для индекса с подсказками получился такой, немного дублирующийся, маппинг:
Вес для каждой новой подсказки устанавливается в единичку и увеличивается при каждом повторном вводе с помощью Update By Query API с очень простым скриптом ctx._source.suggest.weight++.
А вот документов и возможных комбинаций прав может быть ну очень много. Поэтому тут мы, наоборот, решили при автодополнении фильтрацию по правам не делать, но индексировать только общедоступные документы. Да и удалять отдельные подсказки из этого индекса не надо. Казалось бы, реализация во всём легче предыдущей, если бы не два момента:
Первый — Completion Suggester поддерживает только префиксный поиск, а клиенты так любят присваивать всему номенклатурные номера, и какой-нибудь ЖПА.01.01 Правила сокращения слов по мере ввода запроса Правила сокращения не найти. Тут вместе с полным именем можно индексировать и производные от него n-граммы:
С историей это было не так критично, всё же один и тот же пользователь вводит примерно одну и ту же строку, если ищет что-то повторно. Наверное.

Второй — по умолчанию все подсказки равны, но нам бы хотелось некоторые из них сделать равнее и желательно так, чтобы это было согласовано с ранжированием результатов поиска. Для этого надо примерно повторить функции gauss и field_value_factor, используемые в Function Score Query.
Получается вот такой pipeline:
со следующим скриптом:
Зачем вообще городить pipeline с painless вместо того, чтобы написать это на более удобном языке? Потому что теперь с помощью Reindex API в индекс для подсказок можно перегнать содержимое поисковых индексов (указав только нужные поля, разумеется) буквально в одну команду.
Состав действительно нужных общедоступных документов обновляется не часто, поэтому эту команду можно оставить на ручном запуске.
Отображение результатов
Категория определяет, какие фасеты будут доступны и как будет выглядеть сниппет. Может быть определена автоматически внешним интеллектом или выбрана вручную над строкой поиска.
Фасеты
Фасеты — это такая интуитивно понятная всем штука, поведение которой, тем не менее, описывается весьма нетривиальными правилами. Вот несколько из них:


В эластике фасеты реализуются через механизм агрегаций, но для соблюдения описанных правил эти агрегации приходится вкладывать друг в друга и друг другом же фильтровать.

Рассмотрим фрагменты запроса, ответственные за это:
Слишком большой кусок кода
Что тут что:
Сниппеты
В зависимости от выбранной категории сниппет может выглядеть по-разному, например, один и тот же документ при поиске в категории


Или помните, мы хотели видеть предмет коммерческого предложения и от кого оно поступило?

Чтобы не тащить с эластика всю карточку целиком (это замедляет поиск), используется Source filtering:
Для подсветки найденных слов в тексте документа используется Fast Vector highlighter — как генерирующий наиболее адекватные сниппеты для больших текстов, а для наименования — Unified highlighter — как наименее требовательный к ресурсам и структуре индекса:
При этом наименование подсвечивается целиком, а из текста достаем до 3 фрагментов длиной 300 символов. Текст, возвращаемый Fast Vector highlighter’ом, дополнительно сжимается самодельным алгоритмом для получения минимизированного состояния сниппета.
Коллапс
Исторически пользователи этой ECM привыкли, что поиск возвращает им документы, но на самом деле Elasticsearch ищет среди версий документов. Может получиться, что по одному и тому же запросу будут найдены несколько почти одинаковых версий. Это будет захламлять результаты и вводить пользователя в недоумение. К счастью, избежать такого поведения можно при помощи механизма Field Collapsing — некоторого облегченного варианта агрегаций, который срабатывает уже на готовых результатах (в этом он напоминает post_filter, два костыля — пара). Результатом коллапса станет самый релевантный из сворачивающихся объектов.
К сожалению, коллапс обладает рядом неприятных эффектов, например, различные численные характеристики результата поиска продолжают возвращаться такими, как будто никакого коллапса не было. То есть, число результатов, количество по значениям фасет — все будут слегка неправильные, но пользователь этого обычно не замечает, как и уставший читатель, который вряд ли дочитал до этого предложения.
Как увеличить индекс производительности Windows 7 и прочих версий системы?
Предлагаем вам несколько проверенных методов, которые, вероятно, не сделают компьютер намного быстрее, но помогут в некоторой мере оптимизировать его работу.
Попробуйте следующие способы:

Теперь вы знаете, как повысить индекс производительности Windows 7, 8 и 10. Само понятие индекса — действительно полезный инструмент, знать о котором нужно каждому пользователю. Можем сделать вывод, что используя его, вы сможете своевременно понять, стоит ли вам поменять процессор или увеличить объём оперативной памяти. И ещё, всегда пробуйте ускорить компьютер вышеописанными подручными средствами, чтобы он служил как можно дольше.
Открывайте файлы с расширением INDEX быстро и легко. 4 шага
Это может быть очень неприятно, когда у вас есть файл INDEX, и вы не можете открыть его. Но не волнуйтесь, в большинстве случаев решение вашей проблемы очень простое. Следуйте инструкциям в шагах 1-4, перечисленным ниже, и вы сможете решить вашу проблему и легко открыть файл INDEX.
INDEX расширение файла
INDEX значок файла должен отображаться способом, характерным для программы, поддерживающей такой тип файла. Если значок INDEX file имеет форму обычного значка пустой страницы или аналогичного, это означает, что данный формат не связан ни с одной программой, установленной в системе. Ниже перечислены некоторые из наиболее популярных причин такой ситуации.
Проверьте INDEX файл на наличие ошибок
Чтобы решить следующие проблемы, следуйте инструкциям:
Шаг 1. Выберите, загрузите и установите соответствующее программное обеспечение. Список программ, поддерживающих файлы с расширением INDEX, можно найти ниже:
Индекс производительности Windows — как его узнать и повысить на своём компьютере
Индекс производительности — это показатель работоспособности Windows, основывающийся на эффективности важных составляющих компьютера. Это число показывает, насколько хорошо работает устройство и может подсказать, что необходимо сделать для ускорения работы.
Индекс производительности Windows существует для того, чтобы пользователь мог реально оценить возможности своего ПК
Скорость работы — то, что интересует большинство пользователей. Каждый желает, чтобы система шустро реагировала на процессы, без неполадок и глюков. Давайте же узнаем, как посмотреть индекс производительности Windows 10 и предыдущих версий этой системы, и какие меры можно предпринять для улучшения этого показателя.
Скачивание программы

Рекомендованный софт
Программа для наблюдения за компьютерами в локальной сети: скриншоты, работа в программах, сайты, кейлоггер, почта. Выявит «крыс», повысит дисциплину.
Полезные программы
Пакет программ VentaFax for Windows предназначен для работы с факс-модемами в среде MS Windows 95, 98, Me, NT, 2000 и XP.
Quake — культовая компьютерная игра в жанре шутера от первого лица, разработанная id Software.
Для чего нужен файловый формат. INDEX?
Выступая в качестве расширения имени файла, текстовая строка «.string» служит для указания на тот факт, что данный файл является индексом какого-то вида, обозначая при этом обобщенный тип файлов «Индексный файл» (.index и др.). В вычислительной технике индексы используются для создания баз данных с возможностью быстрого поиска по отношению к другому цифровому содержимому, которое, как правило, намного больше по размеру и непосредственный поиск в котором затруднен либо требует слишком много времени. Индексы (.index и др.) позволяют оперативно осуществлять поиск и управление большими массивами данных, а также контролировать процессы, связанные с непрерывной обработкой больших объемов информации (например, восстановление данных).
Что такое Z-index и как им управлять
Файл .index представляет собой индекс, созданной какой-либо компьютерной программой для своих нужд. Кроме общего расширения .index, для обозначения индексных файлов используются и другие расширения. В зависимости от приложения, индексные файлы могут создаваться во множестве различных форматов: от простого текста до сложных двоичных структур. Индексные файлы имеют смысл и могут использоваться только совместно с индексированным содержимым. Как правило, все индексные файлы (.index и др.) создаются и обновляются соответствующим программным обеспечением автоматически без необходимости каких-либо действий со стороны пользователя.
Элементы интеллектуальности
Умный поиск — это как раз тот случай, когда количество может перейти в качество и множество небольших и достаточно простых фич может сформировать ощущение магии.
Как посмотреть индекс производительности на Windows 10
Если вы обладаете последней версией обеспечения, вы опять-таки, можете воспользоваться отдельными утилитами для оценки производительности — например, Winaero WEI tool.
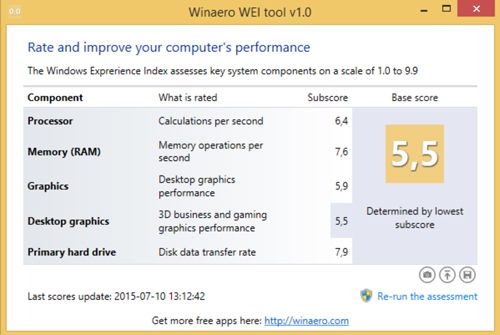
Или посмотрите информацию так:
Допустим, вы узнали, как проверить индекс производительности Windows 10, и выяснили, что он довольно плох.
Что делать? Прежде всего, сама система указывает, какие составляющие тормозят работу системы. Если вам казалось, будто графика не очень хорошо работает, и по оценке она отстаёт от остальных показателей, это наверняка убедит вас, что пора таки менять эту составляющую.
Но, стоит попробовать немного ускорить свой ПК и без замены деталей.
Как устроено индексирование баз данных
Время на прочтение

Индексирование баз данных — это техника, повышающая скорость и эффективность запросов к базе данных. Она создаёт отдельную структуру данных, сопоставляющую значения в одном или нескольких столбцах таблицы с соответствующими местоположениями на физическом накопителе, что позволяет базе данных быстро находить строки по конкретному запросу без необходимости сканирования всей таблицы. Применяются разные типы индексов, однако они занимают пространство и должны обновляться при изменении данных. Важно тщательно продумывать стратегию индексирования базы данных и регулярно её оптимизировать.
Что значит индекс производительности системы Windows
Индекс производительности Windows определяет возможности конфигурации оборудования и программного обеспечения компьютера и отображает их в виде числа, называемого базовым значением. Высокое базовое значение обычно означает, что компьютер будет работать лучше и быстрее, особенно при выполнении сложных задач, требующих много ресурсов, чем компьютер с более низким базовым значением.
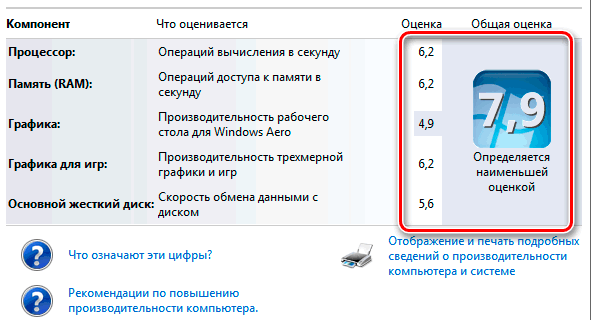
Каждый компонент оборудования получает собственное субзначение. Базовое значение определяется по наименьшему. Однако, субоценки показывают, как работают важнейшие компоненты, и помогает решить, какие из них нужно обновить.
Общую оценку компьютера можно использовать при покупке программ и другого программного обеспечения, которое соответствует этой оценке. Например, если общая оценка компьютера составляет 3,3, то можно покупать любое программное обеспечение, разработанное для этой версии Windows, которое требует общую оценку 3 или меньше.
Текущий диапазон оценок имеет значение от 1,0 до 9,9. Индекс производительности Windows разработан с учетом дальнейшего развития компьютерных технологий. Поскольку быстродействие и производительность оборудования улучшаются, диапазон оценок увеличится. Стандарты для каждого уровня индекса в целом остаются неизменными. Однако, могут быть разработаны новые тесты, которые снизят оценки.
Как узнать индекс производительности на разных версиях Windows?
Для начала стоит уточнить, что такое понятие появилось не сразу, а начиная с Vista, но иначе реализуется в разных версиях Windows. Если в седьмой и восьмой версиях информацию было легко найти, то в следующем программном обеспечении её спрятали дальше, и просто так данных не увидеть.
Предлагаем для начала выяснить путь к индексу производительности, а затем уж решать, что с ним делать.
Как узнать индекс производительности на других версиях Windows?
Чтобы посмотреть оценку вашего ПК на Windows 8.1, выполните следующее:
В строках поочерёдно перечислены данные об общей производительности, оперативной памяти, процессоре, графике, диске и прочие, менее важные данные.
Альтернативные способы
Ещё оценка производительности на Windows 8.1 просматривается через командную строку — кликните правой кнопкой по клавише «Пуск» и запустите её с правами администратора. Далее, введите «Get-CimInstance-ClassName Win32_WinSAT» и перед вами появится меню с отметками.
Если на компьютере ранее не выполнялось оценивание скорости работы, введите в коммандере «winsat formal» или «winsat formal -v» — вторая команда запустит более детальный анализ.
Открытие INDEX файлов
У вас есть проблема с открытием .INDEX-файлов? Мы собираем информацию о файловых форматах и можем рассказать для чего нужны файлы INDEX. Дополнительно мы рекомендуем программы, которые больше всего подходят для открытия или конвертирования таких файлов.
Узнаём о производительности в Windows Vista, 7, 8
В этих версиях обеспечения путь к оценке найти легко — просто нажмите правой клавишей мыши на значке «Мой компьютер», выберите «Свойства» и найдите строку «Оценка».
Что обозначает это число, и на основе каких параметров формируется?
В коэффициент входит суммарная оценка таких комплектующих компьютера:
Каждому из пунктов ставится оценка, на основе которой выводится общий показатель эффективности.
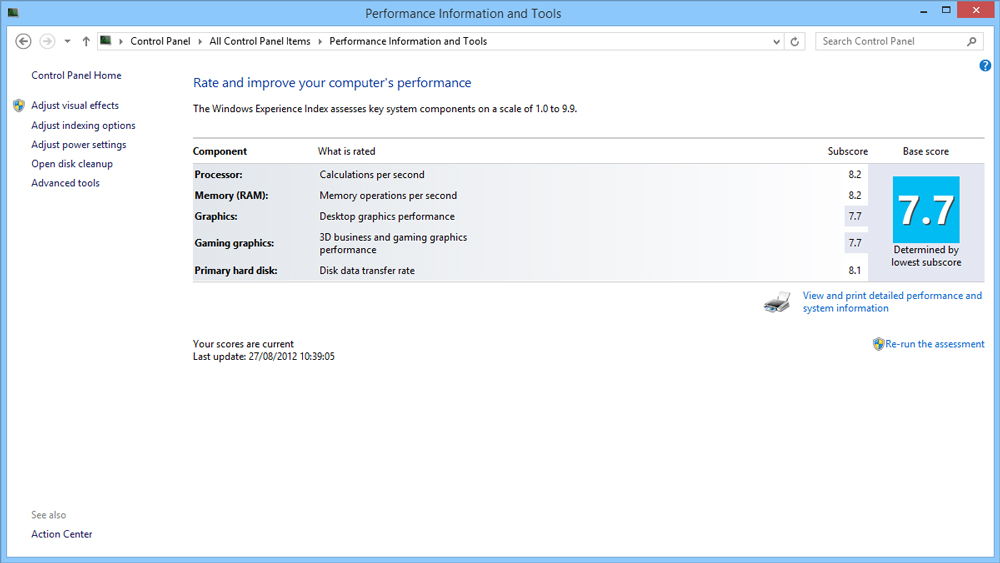
Максимальная оценка может быть следующей:
Когда оценка низкая, и быстродействие не на высоте, можно выяснить почему. Нажмите на «Индекс производительности Windows», и вы увидите полную информацию о том, сколько баллов получила каждая составляющая компьютера.
Далее, в этом же меню вы узнаете, какие комплектующие вам нужно улучшить или заменить, чтобы устройство работало быстрее. Но, конечно, можно частично обойтись и без этого — на этом вопросе мы остановимся далее.
Делаем действительно умный поиск
Статей о том, как к существующей базе прикрутили полнотекстовый поиск на основе Elasticsearch, в интернете уже предостаточно. А вот статей, как сделать действительно умный поиск, явно не хватает.
При этом сама фраза «Умный поиск» уже превратилась в баззворд и используется к месту и нет. Что же такого должна делать поисковая система, чтобы её можно было считать умной? Ультимативно это можно описать как выдачу результата, который на самом деле нужен пользователю, даже если этот результат не совсем соответствует тексту запроса. Популярные поисковые системы вроде Google и Яндекс идут дальше и не просто находят нужную информацию, а напрямую отвечают на вопросы пользователя.
Окей, сразу на ультимативное решение замахиваться не будем, но что можно сделать чтобы приблизить обычный полнотекстовый поиск к умному?
Индекс производительности и принцип его действия
Индекс позволяет оценить работу системы
Задумка индекса производительности заключалась в том, чтобы помочь пользователю проанализировать системные компоненты компьютера и выявить их допустимую эффективность. Впервые индекс производительности появился в операционной системе Windows Vista в качестве графического интерфейса, который показывал общую оценку производительности работы всей системы. Данный индекс отображался в свойствах компьютера путем просмотра его основных сведений. Однако, через некоторое время он утратил свою силу из-за некорректного отображения общего значения производительности. Главной причиной этому стало то, что служебная программа, проанализировав компоненты системы, результатировала не среднее значение производительности в целом, а присуждала компьютеру самую низшую оценку из всех имеющихся компонентов.
Чтобы это было проще понять, приведу наглядный пример. Допустим, служебная программа проанализировала ваши системные элементы и присвоила каждому из них индивидуальную оценку в 8 баллов. Но по каким-то причинам у вас оказался жесткий диск с низкой пропускной способностью и медленной скоростью чтения/записи данных. Вследствие этого служба присвоила данному компоненту 2 балла.
Как итог, программа рассчитает не среднее значение производительности вашего компьютера, а присвоит ему самое минимальное значение из всех существующих компонентов. Результат будет таковым, что индекс производительности компьютера составит 2 балла, несмотря на то, что все остальные компоненты имеют высокую мощность и производительность.
Ввиду этого, начиная с операционной системы Windows 8, служба потеряла свою актуальность и утратила графическую оболочку, но как бы то ни было, осталась действующей и в некотором направлении даже полезной.
Index. dat Suite 2
Кратко: Маленькая программа, которая позволяет просматривать Index.dat — файл с Вашими путешествиями по сети. Прога поможет Вам просматривать и, при.
Index.dat Suite — Маленькая программа, которая позволяет просматривать Index.dat — файл с Вашими путешествиями по сети. Прога поможет Вам просматривать и, при необходимости, удалять файлы: index.dat, временные файлы IE, временные файлы, кукисы и хистори. Возможна дефрагментация после удаления Index.dat.
Расширение файла INDEX

Полное имя формата файлов, которые используют расширение INDEX: Eclipse Help Index. Спецификация Eclipse Help Index была создана The Eclipse Foundation. Файлы с расширением INDEX могут использоваться программами, распространяемыми для платформы Windows. Файлы с расширением INDEX классифицируются как Другие файлы файлы. Подмножество Другие файлы содержит #NUMEXTENSIONS # различных форматов файлов.
Самым популярным программным обеспечением, поддерживающим INDEX файлы, является Eclipse. Программное обеспечение Eclipse было разработано The Eclipse Foundation, и на его официальном веб-сайте вы можете найти дополнительную информацию о файлах INDEX или программном обеспечении Eclipse.
Программы, которые поддерживают INDEX расширение файла
Ниже приведена таблица со списком программ, которые поддерживают INDEX файлы. Файлы с суффиксом INDEX могут быть скопированы на любое мобильное устройство или системную платформу, но может быть невозможно открыть их должным образом в целевой системе.
Программы, обслуживающие файл INDEX

Отсутствие возможности открывать файлы с расширением INDEX может иметь различное происхождение. Что важно, все распространенные проблемы, связанные с файлами с расширением INDEX, могут решать сами пользователи. Процесс быстрый и не требует участия ИТ-специалиста. Ниже приведен список рекомендаций, которые помогут вам выявить и решить проблемы, связанные с файлами.
Шаг 1. Получить Eclipse

Шаг 2. Проверьте версию Eclipse и обновите при необходимости

Если у вас уже установлен Eclipse в ваших системах и файлы INDEX по-прежнему не открываются должным образом, проверьте, установлена ли у вас последняя версия программного обеспечения. Разработчики программного обеспечения могут реализовать поддержку более современных форматов файлов в обновленных версиях своих продуктов. Причиной того, что Eclipse не может обрабатывать файлы с INDEX, может быть то, что программное обеспечение устарело. Последняя версия Eclipse должна поддерживать все форматы файлов, которые совместимы со старыми версиями программного обеспечения.
Шаг 3. Настройте приложение по умолчанию для открытия INDEX файлов на Eclipse
Если у вас установлена последняя версия Eclipse и проблема сохраняется, выберите ее в качестве программы по умолчанию, которая будет использоваться для управления INDEX на вашем устройстве. Следующий шаг не должен создавать проблем. Процедура проста и в значительной степени не зависит от системы
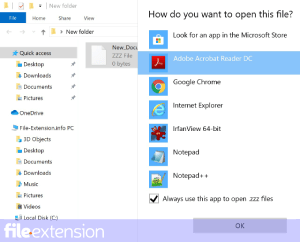
Процедура изменения программы по умолчанию в Windows
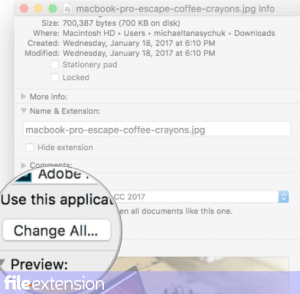
Процедура изменения программы по умолчанию в Mac OS
Шаг 4. Убедитесь, что файл INDEX заполнен и не содержит ошибок
Вы внимательно следили за шагами, перечисленными в пунктах 1-3, но проблема все еще присутствует? Вы должны проверить, является ли файл правильным INDEX файлом. Отсутствие доступа к файлу может быть связано с различными проблемами.

INDEX может быть заражен вредоносным ПО — обязательно проверьте его антивирусом.
Если файл заражен, вредоносная программа, находящаяся в файле INDEX, препятствует попыткам открыть его. Сканируйте файл INDEX и ваш компьютер на наличие вредоносных программ или вирусов. Если сканер обнаружил, что файл INDEX небезопасен, действуйте в соответствии с инструкциями антивирусной программы для нейтрализации угрозы.
Убедитесь, что файл с расширением INDEX завершен и не содержит ошибок
Если вы получили проблемный файл INDEX от третьего лица, попросите его предоставить вам еще одну копию. Возможно, файл был ошибочно скопирован, а данные потеряли целостность, что исключает доступ к файлу. Если файл INDEX был загружен из Интернета только частично, попробуйте загрузить его заново.
Проверьте, есть ли у пользователя, вошедшего в систему, права администратора.
Иногда для доступа к файлам пользователю необходимы права администратора. Переключитесь на учетную запись с необходимыми привилегиями и попробуйте снова открыть файл Eclipse Help Index.
Убедитесь, что ваше устройство соответствует требованиям для возможности открытия Eclipse
Если система перегружена, она может не справиться с программой, которую вы используете для открытия файлов с расширением INDEX. В этом случае закройте другие приложения.
Убедитесь, что ваша операционная система и драйверы обновлены
Современная система и драйверы не только делают ваш компьютер более безопасным, но также могут решить проблемы с файлом Eclipse Help Index. Возможно, что одно из доступных обновлений системы или драйверов может решить проблемы с файлами INDEX, влияющими на более старые версии данного программного обеспечения.
Вы хотите помочь?
Если у Вас есть дополнительная информация о расширение файла INDEX мы будем признательны, если Вы поделитесь ею с пользователями нашего сайта. Воспользуйтесь формуляром, находящимся здесь и отправьте нам свою информацию о файле INDEX.
Чтобы что-то хорошо поискать, нужно это что-то вначале хорошо проиндексировать.
Документы в ECM не статичны, пользователи модифицируют текст, создают новые версии, изменяют данные в карточках; постоянно создаются новые документы и иногда удаляются старые.
Для поддержания актуальной информации в Elasticsearch документы нужно постоянно переиндексировать. К счастью, в ECM уже есть своя очередь асинхронных событий, поэтому при изменении документа достаточно добавить его в очередь для индексирования.
Отображение документов ECM на документы Elasticsearch
Тело документа в ECM может иметь несколько версий. В Elasticsearch это можно было бы представить как массив nested-объектов, но тогда с ними становится неудобно работать — усложняется написание запросов, при изменении одной из версий надо переиндексировать всё, разные версии одного документа не могут храниться в разных индексах (зачем это может понадобиться — в следующем разделе). Поэтому мы денормализуем один документ из ECM в несколько документов Elasticsearch с одинаковой карточкой, но разными телами.
Кроме карточки и тела в документ Elasticsearch добавляется разная служебная информация, в которой отдельно стоит отметить:
Состав индексов
Да, индексов во множественном числе. Обычно несколько индексов для хранения схожей по смыслу информации в Elasticsearch используются только если эта информация неизменяемая и привязана к какому-то временному отрезку, например логи. Тогда индексы создаются каждый месяц/день или чаще в зависимости от интенсивности нагрузки. В нашем случае может быть изменён любой документ, и можно было бы хранить всё в одном индексе.
Но — документы в системе могут быть на разных языках, а хранение мультиязычных данных в Elasticsearch несёт 2 проблемы:
Стемминг — нахождение основы слова. Основа не обязательно должна являться корнем слова или его нормальной формой. Обычно хватает того, чтобы связанные слова проецировались в одну основу.
Лемматизация — разновидность стемминга, в которой основой считается нормальная (словарная) форма слова.
Первую проблему можно решить для случая, когда разные языки используют разные наборы символов, (русско-английские документы используют кириллицу и латиницу) — языковые стеммеры будут обрабатывать только «свои» символы.
Как раз для решения второй проблемы мы использовали подход с отдельным индексом для каждого языка.
Комбинируя оба подхода, получим языковые индексы, которые тем не менее содержат анализаторы сразу для нескольких не пересекающихся по наборам символов языков: русско-английский (и отдельно англо-русский), польско-русский, немецко-русский, украино-английский и т.д.
Чтобы не создавать все возможные индексы заранее, использовали шаблоны индексов — Elasticsearch позволяет задать шаблон, который содержит настройки и маппинги, и указывать паттерн имени индекса. При попытке проиндексировать документ в несуществующий индекс, имя которого подходит под один из паттернов шаблона, будет не только создан новый индекс, но и к нему будут применены настройки и маппинги из соответствующего шаблона.
Структура индексов
Для индексирования используем сразу два анализатора (через multi-fields): default для поиска по точной фразе и custom для всего остального:
С фильтром lowercase всё понятно, расскажу про остальные.
Фильтры russian_morphology и english_morphology предназначены для морфологического анализа русского и английского текста соответственно. Они не входят в состав Elasticsearch и ставятся в составе отдельного плагина analysis-morphology. Это лемматизаторы, использующие словарный подход в сочетании с некоторыми эвристиками и работающие значительно, ЗНАЧИТЕЛЬНО, лучше встроенных фильтров для соответствующих языков.
Очень любопытный фильтр word_delimiter. Он, например, помогает устранять опечатки, когда после точки нет пробела. Используем следующую конфигурацию:
yo_filter позволяет игнорировать разницу между E и Ё:
ru_en_stopwords фильтр с типом stop — наш словарь стоп-слов.
Процесс индексирования
Тела документов в ECM — это, как правило, файлы офисных форматов: .docx, .pdf и т.д. Для извлечения текста используется плагин ingest-attachment со следующим pipeline:
Из необычного в pipeline — игнорирование ошибок отсутствия тела (такое случается для зашифрованных документов) и определение целевого индекса, исходя из языка текста. Последнее делается в painless-скрипте, тело которого я приведу отдельно, т.к. из-за ограничений JSON его приходится записывать в одну строку. Вкупе со сложностями отладки (рекомендуемый способ — генерация исключений там и сям) он и вовсе превращается в painful.
Таким образом, мы всегда посылаем документ в index_name. Если язык не определился или не поддерживается, то в этом индексе документ и оседает, иначе попадает в index_name_language.
Само исходное тело файла мы не храним, но поле _source включено, т.к. оно требуется для частичного обновления документа и подсветки найденного.
Если с момента последней индексации изменялась только карточка, то для её обновления используем Update By Query API без pipeline. Это позволяет, во-первых, не тянуть потенциально тяжелые тела документов из ECM, а во-вторых, значительно ускоряет обновление на стороне Elasticsearch — не приходится извлекать текст документов из офисных форматов, что весьма ресурсоёмко.
Как такового обновления документа в Elasticsearch вообще нет, технически при обновлении из индекса достается старый документ, изменяется и снова полностью индексируется.
А вот если менялось тело, то старый документ вообще удаляется и индексируется с нуля. Это позволяет документам переезжать из одного языкового индекса в другой.
Ваше мнение о программе Index.dat Suite 2.5.8:
Мнения публикуются только после проверки администратором.
Перед добавлением плохого мнения читайте соглашение нашего сайта.Не публикуются мнения: о серийных номерах, креках и т.п., оскробительные или не о “Index.dat Suite 2.5.8”.
Ваше имя: e-Mail:
Оценка: нет 1 2 3 4 5
LanAgent Standard 7.7
Программа для наблюдения за компьютерами в локальной сети: скриншоты, работа в программах, сайты, кейлоггер, почта. Выявит “крыс”, повысит дисциплину.
Quake III Arena
Quake III Arena — культовая компьютерная игра в жанре многопользовательского шутера от первого лица, изданная компанией id Software.
О базовом индексе производительности компьютера
Оценка отражает минимальную производительность системы на основе возможностей различных составляющих компьютера, включая оперативную память (ОЗУ), центральный процессор (ЦП), жесткий диск, общую производительность воспроизведения графики на рабочем столе и возможность воспроизведения объемной графики.
Ниже приведен общий описание возможностей компьютеров с указанными базовыми значениями.
Производительность компьютера с общей оценкой от 1,0 до 2,0 обычно достаточна для выполнения большинства общих вычислительных задач (например, для выполнения программ улучшения офисной производительности и поиска в интернете). Однако, компьютер с такой общей оценкой, в целом, недостаточно мощный для работы в среде Aero и для реализации дополнительных мультимедийных возможностей, доступных в Windows.
Компьютер с общей оценкой 3,0 может работать с Aero и многими средствами Windows 7 на общем уровне. Некоторые дополнительные средства Windows 7 могут работать только в режиме ограниченной функциональности. Например, компьютер с общей оценкой 3,0 может отображать тему Windows 7 разрешением 1280×1024, но с трудом выполнит эту тему на нескольких мониторах. Или может воспроизводить содержимое цифрового телевидения, но с трудом воспроизводить телевидения высокой четкости (HD-телевидение).
Что такое индекс? Как узнать свой индекс?
Компьютер с общей оценкой 4,0 или 5,0 может выполнять новые приложения Windows 7 и поддерживать выполнение нескольких программ одновременно.
Компьютер с общей оценкой 6,0 или 7,0 имеет быстрый жесткий диск и может реализовать вычисления с большим объемом графических операций (например, игра на нескольких участников, объемная игровая графика, а также запись и воспроизведения содержимого HDTV).
Если отдельная программа или работа системы Windows 7 требует более высокого значения, чем имеющееся базовое значение вашего компьютера, можно повысить это значение, обновив оборудование. Чтобы проверить, не изменилось ли базовое значение после установки нового оборудования, выберите Повтор оценки . Чтобы больше узнать об оборудовании на компьютере, выберите Просмотреть и распечатать подробности.
Субзначения индекса компьютера
Субзначения – это результаты проверки возможностей ОЗУ, ЦП, жесткого диска, общей производительности отрисовки графики на рабочем столе и компонентов оборудования игровой объемной графики на компьютере. Если общая оценка недостаточна для выполнения определенной программы или работы в Windows, то с помощью субоценок можно определить, какие компоненты требуется обновить.

